














リアルタイムシステムでPCI Expressを適用するために必要な高精度同期技術について
- PLC
- リアルタイムシステム
- PCI Express
- 時刻同期
- DMA
オムロンが開発するマシンオートメーションコントローラのNJシリーズやNXシリーズでは、内部のCPU(Central Processing Unit)と構成するデバイス間がPCIe(PCI Express)を用いて接続されている。PCIeの特長としてDMA(Direct Memory Access)を用いてCPUを介さずに直接メモリアクセスを実行し、データ転送を実行することが可能である。マシンオートメーションコントローラといったリアルタイムシステムにPCIeを導入するためには、メモリリソースが競合しないようにDMA転送タイミングを制御する必要がある。
従来は1つのCPUによる集中制御であったため、DMA転送タイミングの制御が容易であり、メモリリソースが競合しないように制御することができていた。近年のリアルタイムシステムでは多機能でありつつ高速・高精度な制御性能が求められている。これらを両立するために複数のPCIeデバイスがCPUとの間でDMA転送する分散処理アーキテクチャが必要となる。リアルタイム処理に影響を与えないようにするためには、各PCIeデバイスが制御周期と高精度に同期したタイミングでデータ転送を行う必要がある。
本稿ではPCIeデバイスがCPUとのリソース競合を回避する技術とその技術を実現するために必要不可欠であるハードウェアによる高精度時刻同期技術を提案する。それにより39ナノ秒以下という時刻同期精度を実現することができ、複数のPCIeデバイスがCPUとDMA転送する際にリアルタイム処理への影響を抑えられる。
1. まえがき
オムロンが開発しているマシンオートメーションコントローラ1)のNJシリーズやNXシリーズ(以下、コントローラ)は高速高精度な制御を実現するリアルタイムシステムである。コントローラは複雑な制御処理を高速に実行するために高性能な汎用CPU(Central Processing Unit、以下汎用CPU)を用いてリアルタイム制御処理を実行している。汎用CPUを用いることで、世の中の半導体技術の進化に追従してその処理性能の向上を図ることができている。しかし、汎用CPUはリアルタイムシステムに専用設計されているわけではないため、定周期かつ低遅延で制御を実行するために必要なタイマ回路がほとんど実装されていない。低遅延で処理を実行するためにはタイマ割込み発生の都度どの処理を実行するのかを判断するのではなく、処理に対応したタイマ割込みを発生させることが望ましいため、複数のタイマ回路が必要となる。汎用CPUを使用するだけでは、リアルタイムシステムを制御するために必要なタイミングを精確に複数発生させることが難しいといった課題がある。
この課題を解決するために、コントローラでは独自のタイマデバイス(以下、タイマデバイス)を搭載している。タイマデバイスには複数のタイマ回路が実装されており、リアルタイムシステムを制御するために必要なタイミングで精確な割り込みを複数発生させることができる。その割り込みに応じて汎用CPUが処理を実施することにより、定周期かつ低遅延な処理を実現している。
汎用CPUは一般的にPCI Express2)(Peripheral Component Interconnect Express 以下、PCIe)という広帯域な汎用バスインターフェースが外部デバイスと接続する標準バスとなっている。コントローラにおいても汎用CPUとタイマデバイスとの接続にはPCIeを使用している。
また、コントローラではタイマデバイス以外に汎用CPUからフィールドバスやローカルバスへアクセスするインターフェース変換デバイスとの接続にもPCIeを使用している。汎用CPUとPCIeデバイス間のデータ転送においては、汎用CPUがPCIeデバイスに対してReadまたはWriteを指示するプログラム転送によって汎用CPUが持つメモリとPCIeデバイスとの間でデータの転送が実施される。しかし、データ転送のためには汎用CPUが指示する必要があり、転送オーバーヘッドが大きい上に汎用CPUの演算リソースが消費されるといった課題がある。
その課題の解決のために一般的にPCIeの通信ではDMA(Direct Memory Access)転送という汎用CPUの演算処理部分を経由せずにデバイス間で直接的にメモリ領域のデータにアクセスできる機能を使用する。DMA転送を活用することによって、汎用CPUの演算処理に負荷をかけずに汎用CPUが持つメモリとPCIeデバイス間でデータを高速に転送することができる。
近年ではコントローラにはリアルタイム性が必要な制御処理以外にも他デバイスとの通信など非リアルタイムの機能追加の要望がある。それらの非リアルタイム機能をコントローラに搭載することにより、汎用CPUの演算処理の負荷が上昇している。リアルタイム処理と非リアルタイム処理が1つのCPUに共存することでリソース競合が発生し、制御処理のリアルタイム性能へ及ぼす影響が顕著になりつつある。そうした中、コントローラを始めとするリアルタイムシステムにおいては、非リアルタイム処理を制御処理用CPU(以下、制御用CPU)とは別のCPU(以下、非リアルタイム用CPU)で制御処理以外の処理を実行する分散アーキテクチャが考えられている。分散アーキテクチャの一形態として、非リアルタイム用CPUと制御用CPUがPCIeによって接続され、DMAを使用したデータ交換を実現するアーキテクチャがある。
非リアルタイム用CPUから制御用CPUへのデータ転送は制御周期とは非同期で行うが、PCIeの標準機能にはデータ転送タイミングを制御する仕組みがない。データ転送タイミングによっては制御用CPUが重要な制御処理実行中にデータ転送されることでメモリアクセスに関するリソース競合が発生し、制御処理に影響する懸念が生じている。データ転送による制御処理への影響を最小化するためには、制御処理の重要な処理期間を避けてデータ転送を行えば良い。そのためには制御処理とDMA転送のタイミングを高精度に同期して制御する必要がある。
この機能を実現するため本稿では、複数のPCIeデバイス間において精確な時刻同期を実現する技術と、DMA転送タイミングを制御する技術の組み合わせによるデータ転送方法を提案する。
2. リアルタイムシステムにおけるPCIeの利用
2.1 コントローラの従来構成
リアルタイムシステムを実現する上で必要となるインターフェース変換機能とタイマ機能を持ったデバイス(以下、リアルタイムサポートデバイス)とコントローラの汎用CPUで構成される従来のコントローラシステムの構成図を図1に示す。汎用CPUとリアルタイムサポートデバイスはPCIeを介して接続されており、汎用CPU側がPCIeのRP(Root Port)、リアルタイムサポートデバイス側がPCIeのEP(Endpoint)として接続されている。
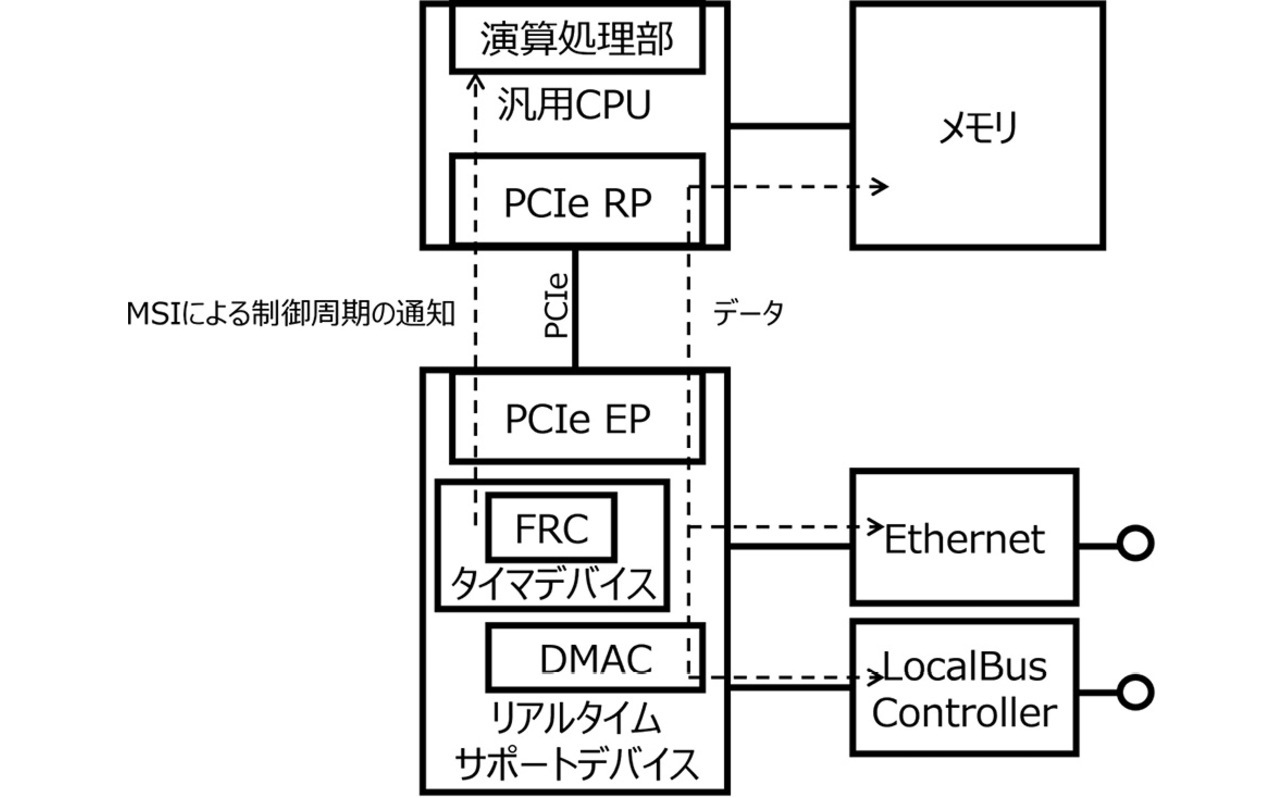
図1に示すようにリアルタイムサポートデバイスはその内部にタイマデバイスを有している。タイマデバイス内にはFRC(Free Run Counter)と呼ぶカウンタを持っている。FRCは時刻情報としてナノ秒単位で常に高精度にカウントアップしている。タイマデバイスは事前に設定した値にFRCが達すると、PCIeが持つ機能の一つであるMSI(Message Signal Interrupt)を用いて汎用CPUに対して割り込みを通知する。汎用CPUは割り込み通知を受けることによって、割り込みを起点にして制御処理を実行することができる。
タイマデバイスは高精度なFRCを元に割り込みを一定周期で発生させることができるため、汎用CPUは定周期に制御処理を実行することができる。
さらにリアルタイムサポートデバイス内には、図1に示すように外部IFやコントローラのローカルバスへのデータ転送デバイスとしてDMAC(DMA Controller)を有している。汎用CPUがPCIeを介してDMACにDMA転送の指示を与えることで外部IFであるEthernetやローカルバスへのデータ転送を制御に影響のないタイミングで実行することができる。
2.2 コントローラの分散処理システムへの進化
近年ではコントローラには制御以外に通信など他の機能の搭載も要求されてきている。これらの要求に応えるため、コントローラには制御以外の機能の搭載が進められている。しかし、追加される機能には高い演算処理性能が求められる場合が多く、追加機能を搭載することにより制御処理に悪影響が発生するといった課題が発生してきている。
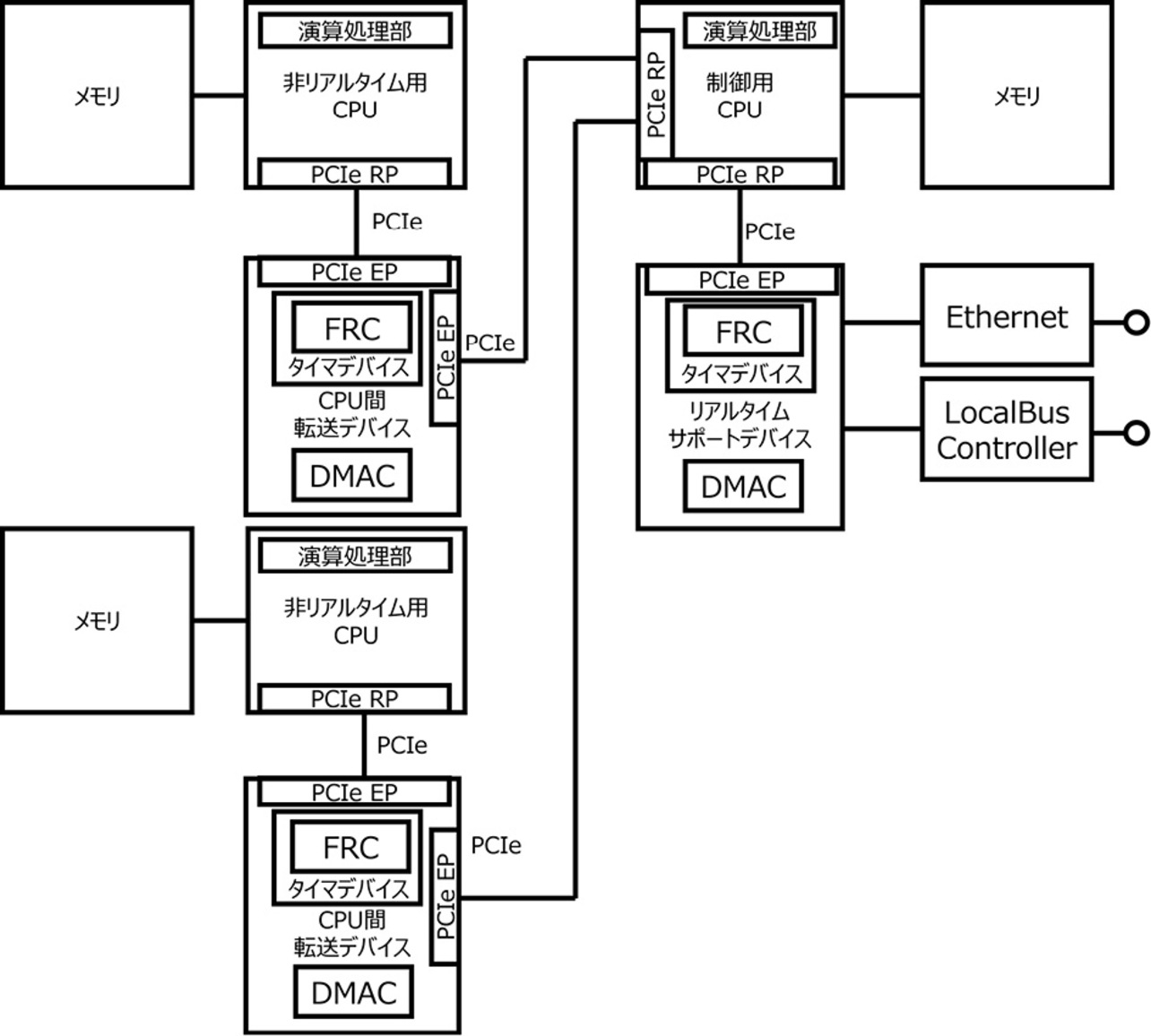
制御性能と追加機能を両立するために、コントローラを始めとしたリアルタイムシステムでは、追加機能を非リアルタイム用CPUへオフロードする分散処理システムへの進化が考えられる。図2に分散処理を実施するためのリアルタイムシステムにおける汎用CPU間の接続例の図を示す。非リアルタイム用CPUと制御用CPUは、DMACを内蔵したCPU間転送デバイスを介してPCIeで接続されている。1つの制御用CPU対して非リアルタイム用CPUは複数台接続することが可能である。非リアルタイム用CPUを複数台接続することで追加する機能の規模に応じてシステムを拡張することができる。非リアルタイム用CPUはCPU間転送デバイスのDMACを使用して制御用CPUとデータ交換を行う。これにより、それぞれのCPUの演算処理部を介さずに必要なデータ転送を行うこととなり、演算処理への負荷を低減した状態でのデータ転送が可能となっている。
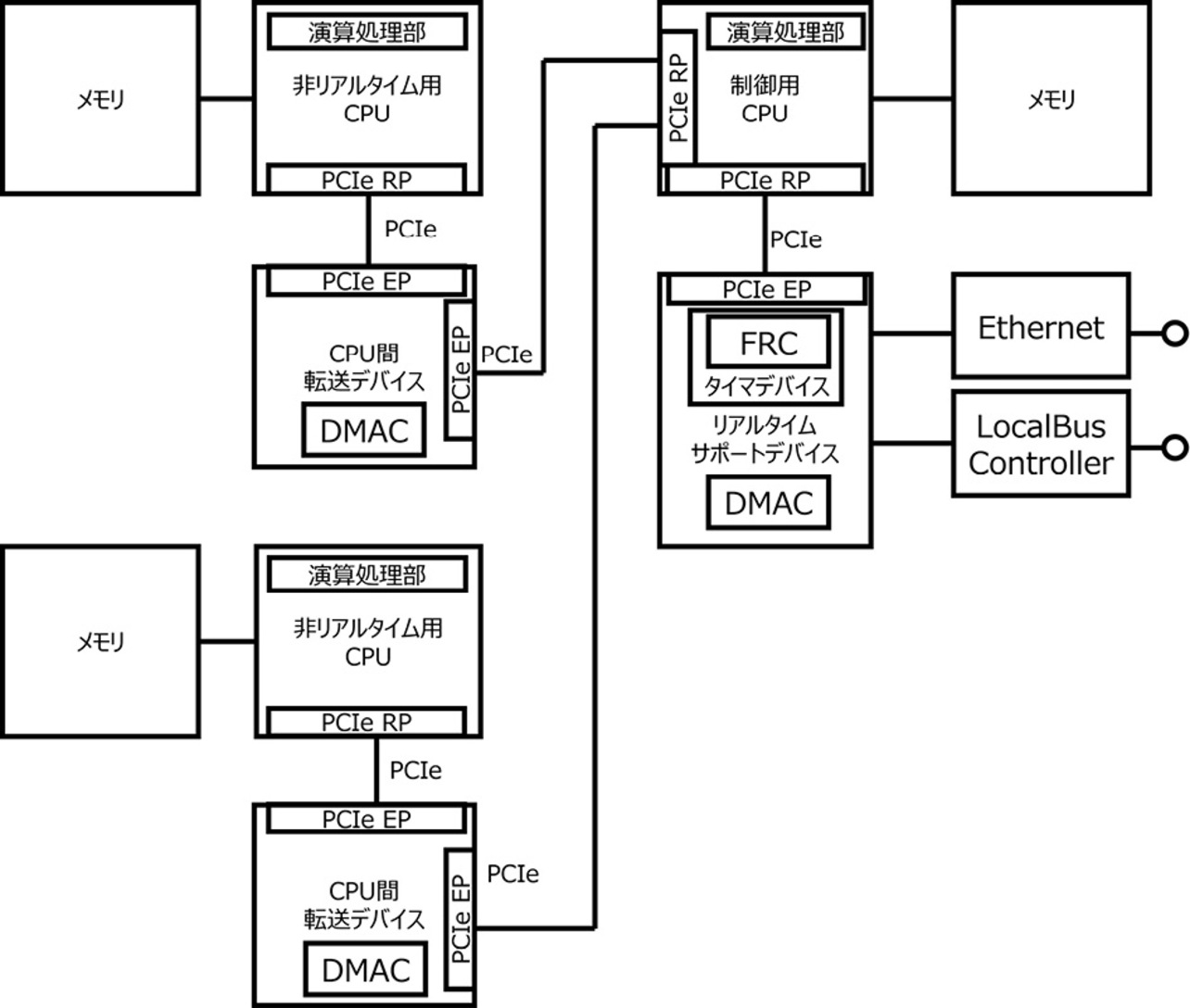
図2に示す構成においては、非リアルタイム用CPUが持つメモリと制御用CPUが持つメモリとの間でDMAによる転送が実施される。DMACによるデータ転送の実施タイミングはDMACを起動するタイミングによって決まる。非リアルタイム用CPUは制御用CPUがリアルタイム処理をしているタイミングかどうかに関わらずDMACを起動するため、データ転送は制御処理と非同期に行われることになる。リアルタイム処理中に制御用CPUは頻繁にメモリにアクセスをしており、リアルタイム性を維持するためにはリアルタイム処理中にメモリアクセスを阻害しないことが重要になる。非リアルタイム用CPUからのDMAによるメモリアクセスが制御用CPU内部におけるリアルタイム処理中に実施された場合、制御用CPU内部でリソース競合が発生し、リアルタイム処理が規定時間内に終了しない可能性が発生する。さらに制御用CPUに複数の非リアルタイム用CPUが接続されるシステムにおいては、DMAによるデータ転送量も増加して制御用CPUのリアルタイム性能に及ぼす影響はより増大することになる。
2.3 PCIe RP間接続のためのDMAC構成における課題
DMA転送するための指示は制御用CPU及び非リアルタイム用CPUともにFW(Firmware)で実現している。DMA転送に必要な転送先のメモリアドレスを入手するためにはFWが転送先とハンドシェークを行って、これを取得する必要がある。FWによるDMA転送制御を簡略化するためには転送先アドレスを把握しなくても制御用CPUと非リアルタイム用CPU間でDMAによる転送が実行できるようにすることが望ましい。これを実現するCPU間転送デバイスのDMAC部分として、図3に示すようなTX側DMACとRX側DMACを備えた構成3)が考えられる。各CPUがそれぞれRX側DMACを制御するため、各CPUが管理するメモリアドレスをRX側DMACに設定することができる。
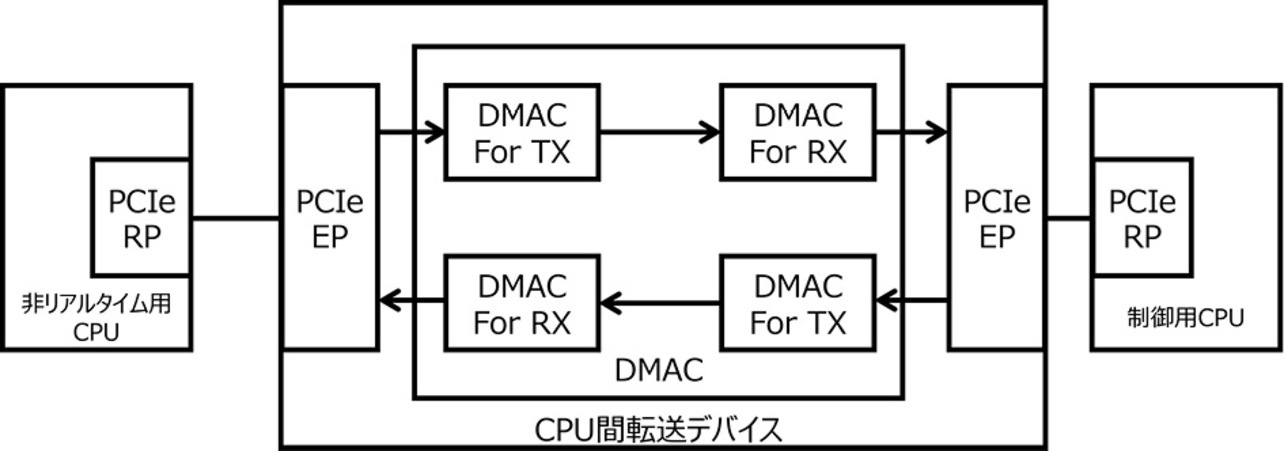
リアルタイムシステムでは、制御処理を実行する際には処理に必要なデータが全て揃っている必要があるため、送信したデータが確実に相手側で受信されていることが重要である。そのため各CPUはそれぞれのRX側DMACを起動し、受信可能状態にしておく。これにより、データ送信時においてCPU間転送デバイス内に送信データを滞留させることなくメモリ領域に送信することができ、送信した直後に確実に相手側で受信することができる。
データを転送する際はそれぞれのCPUがそれぞれのTX側DMACを起動する。TX側DMACはそれぞれのCPUのメモリからデータを取得し、RX側DMACへ渡し、相手先のメモリへデータを転送する。これにより送信する際のタイミングはそれぞれのCPUが決めることができる。制御用CPUはリアルタイム性に影響のある処理をしている期間は、DMACを起動しないことによってデータ送信を抑制することが可能である。一方で受信については、DMACを常に受信可能状態にしておく必要があるため、受信するデータの転送を止めることはできない。制御用CPUへデータが転送されてくるタイミングは非リアルタイム用CPU側DMACの送信タイミングに依存する。その結果、DMA転送タイミングによって制御用CPUのリアルタイム性能に影響を与えるといった課題が発生する。
3. 提案する手法と新たに発生する課題
先出のDMA転送タイミング課題の解決には、各PCIeに接続されるDMAが制御用CPUのリアルタイム処理期間を避けて転送する必要がある。これを実現するために、制御用CPUと高精度に時刻同期するタイマ機能と、このタイマにより転送タイミングを自動で制御するDMACによるデータ転送手法を提案する。
3.1 DMACの転送タイミング制御
リアルタイム処理への影響の最小化を目的として、非リアルタイム用CPUから制御用CPUへのデータ転送の中断/再開を自動で行うDMA転送マスク機能4)を提案する。
図4にDMA転送マスク機能のタイミングチャートを示す。転送マスク機能はCPU間転送デバイスが有する。マスクタイミングをリアルタイムサポートデバイスからHWによる信号によって配信する方法もあるが、この方法ではCPU間転送デバイスが増える毎にマスク信号を追加する必要がある。HWの変更無く柔軟に複数のCPU間転送デバイスに転送マスク機能を追加するために、CPU間転送デバイスでマスクタイミングを生成する方式とする。転送マスクがONの状態ではCPU間転送デバイスは非リアルタイム用CPUから制御用CPUに対してDMA転送を一時停止させる。一時停止はCPU間転送デバイスのRX側DMACに対して、次のPCIeパケットの送出を停止させることで実現する。転送マスクがOFFとなった後、DMA転送を再開させる。PCIeはデータの塊をパケットとして転送しており、パケットの途中で転送を停止できない。一時停止時に即座に転送を停止し、リアルタイム処理への影響を最小限に抑えるために、PCIeのパケットサイズを最小の128 Byteとする。それによってパケット数が増えるために転送効率が悪化し転送帯域は低下するが、転送マスクがONになってからDMA転送が一時停止するまでに時間を最小化することができ、リアルタイム処理の定周期性を確保しやすくなる。
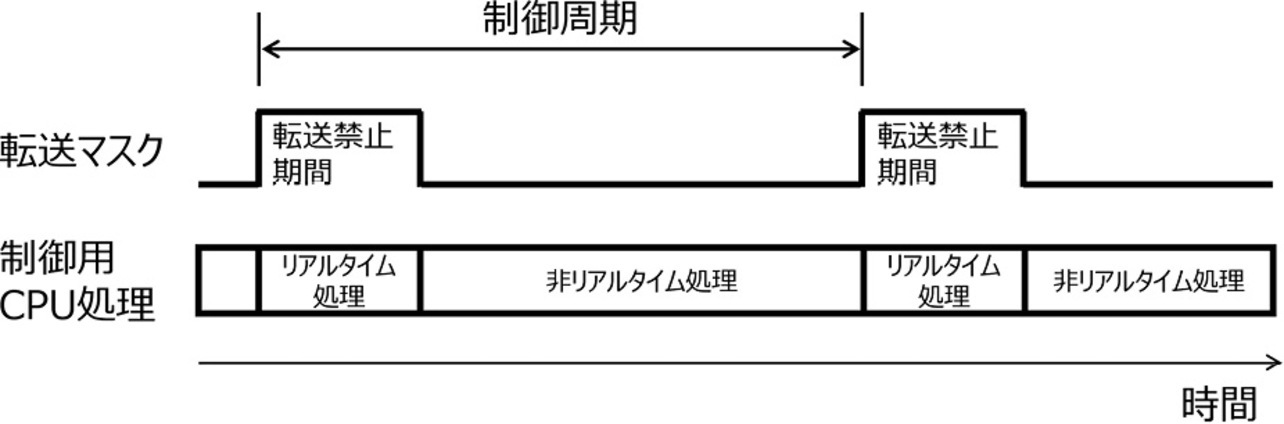
転送マスクはCPU間転送デバイスごとに複数設定することができる。制御用CPUに複数の非リアルタイム用CPUが接続されていても、DMA転送タイミングを個別に設定することが可能なため、メモリ競合を低減させることが可能となる。
3.2 PCIeノード間の高精度時刻同期と新たに発生する課題
前述したDMA転送マスク機能は制御用CPU上のFWがマスクの開始時刻と終了時刻をCPU間転送デバイスに設定することによって、CPU間転送デバイス内のFRCがその設定値と一致したタイミングでDMA転送の一時停止/再開を制御するものである。この場合、制御用CPUは制御サイクルごとに新たなマスク設定値をCPU間転送デバイスに設定する必要があり、FWの負荷となる。この課題を解決するため、CPU間転送デバイスがDMA転送マスク機能の設定値を周期的に更新する構成とする。すなわち、コントローラは定周期で動作しているため、制御用CPU上のFWからCPU間転送デバイスに対して、周期と転送禁止期間の初期設定を行うことでDMA転送マスク機能は制御周期と同期されたタイミングで有効に機能する。初期設定以降はFWによる周期的にマスク設定すると言った制御は不要となる。このDMA転送マスク機能を制御周期に同期して機能させるためには、図5に示すようにCPU間転送デバイスにタイマデバイスを持たせ、リアルタイムサポートデバイスのタイマデバイスとCPU間転送デバイスのタイマデバイスのタイマ値が高精度に同期する必要がある。コントローラと外部機器間の制御で要求される同期精度は1マイクロ秒以下である。この同期精度を達成するためにコントローラの設計としては制御処理の揺らぎをその10%以下である100ナノ秒以下に抑えることを目標とする。
この目標を実現するためには、タイマデバイス間の高精度な時刻同期が不可欠である。DMA転送を一時停止させたいタイミングによっては、最大で128 Byteの転送が行われた後にDMA転送が実際に停止される。すなわち、転送が停止するまでの最大時間はPCIe Gen1 X1で128 Byteを転送する時間に等しい61ナノ秒となる。機器間の同期精度の目標値が100ナノ秒以下であることから、DMAの一時停止にかかる最大時間である61ナノ秒を考慮し、リアルタイムサポートデバイスのタイマデバイスとCPU間転送デバイスのタイマデバイスのタイマ値が39ナノ秒以下という高精度で時刻同期することをタイマデバイス間の同期目標とする。各タイマデバイスの高精度な時刻同期は、タイマの基準となるFRCが高精度に値を同期することで実現できる。
CPU間転送デバイスとリアルタイムサポートデバイスではそれぞれ独立した基準クロックを使用するため、各基準クロックの偏差によってそれぞれのFRCが徐々にずれていく現象が発生する。基準クロックに使用されるクロック発振器は比較的精度の良いもので1ミリ秒につき最大で±25ナノ秒程度の偏差を持っている。これらの発振器を図5に示すCPU間転送デバイスにタイマデバイスを搭載した構成の基準クロックとして採用した場合、CPU間転送デバイス側のクロックとの精度は、1ミリ秒につき2倍の最大±50ナノ秒ずれる可能性がある。各CPU間転送デバイスのFRC値を高精度に同期するためには、定期的にCPU間転送デバイスのFRCの値を、基準となるリアルタイムサポートデバイスのFRCの値に補正をする処理が必要である。従来において採用していた時刻同期の実装方法ではFWが各FRCの時刻情報を取得し、対象のFRCを定期的に補正していた。高精度にFRC値を同期するためには補正周期を短くする必要があるが、これは制御用CPUの演算リソースの消費増大につながり制御性能に影響が出てしまう。
一例として、FWで時刻同期することを想定して8ミリ秒に1回補正を行ったケースを考えると、その8ミリ秒の間に最大±400ナノ秒のずれが発生する可能性がある。前述した通り必要な同期精度は39ナノ秒以下のため、±400ナノ秒の時刻情報のずれは大きな課題となる。その解決策として高精度時刻同期技術を提案する。
4. 高精度時刻同期課題解決手法の提案
4.1 HWによる時刻同期
前述のDMA転送マスク機能を高精度に機能させるためには、PCIeデバイス同士が同じ時刻情報を持って、正確に同期する必要がある。従来においてデバイス間の時刻同期にはいくつかの手法が取られている。その手法の1つを図6を用いて説明する。プライマリとなるFRCを持ったデバイスからトリガ信号を出力する。プライマリ/レプリカ双方のFRCはトリガ信号の受信時の値を保存する。それぞれの保存した値を比較し、その差分をレプリカのFRCに対して補正をかけることで時刻を同期させている。
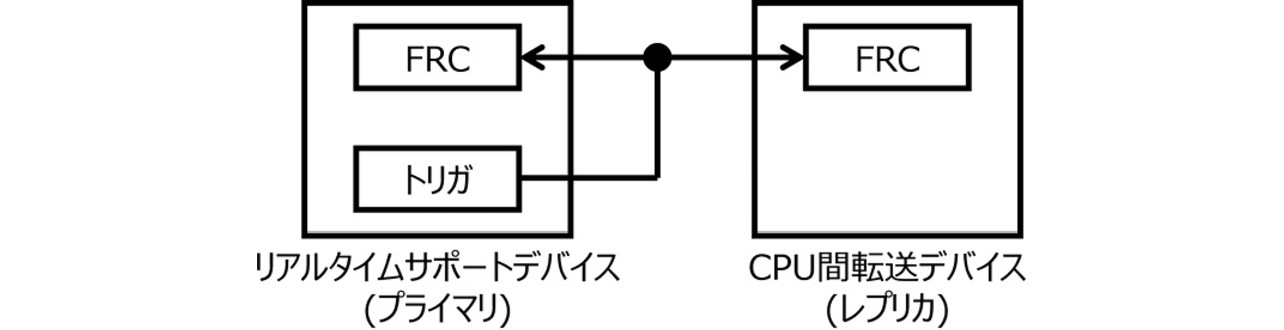
従来はFWによって、プライマリに対してトリガ発行を指示する。その後FWがプライマリ/レプリカのFRCの値を取得し、FWが取得したFRCの値の差分を元にレプリカのFRC補正していた。この方法は定期的に高頻度に行う必要があり、FWの負荷が増大する傾向がある。FWの負荷を軽減し、より高速に時刻補正を行うためにHW(Hardware)によって処理を実現5)することを提案する。
図7にHWによる時刻補正の構成図を示す。プライマリはトリガ発行に応答してFRCの値を取得し、その値をPCIeとは独立した1本の専用線を用いた非同期シリアル伝送にてレプリカに直接転送できる構成とした。レプリカが複数存在している状態においても、プライマリからのFRCデータ送信は複数のレプリカに対してマルチドロップ接続によってブロードキャストされる。
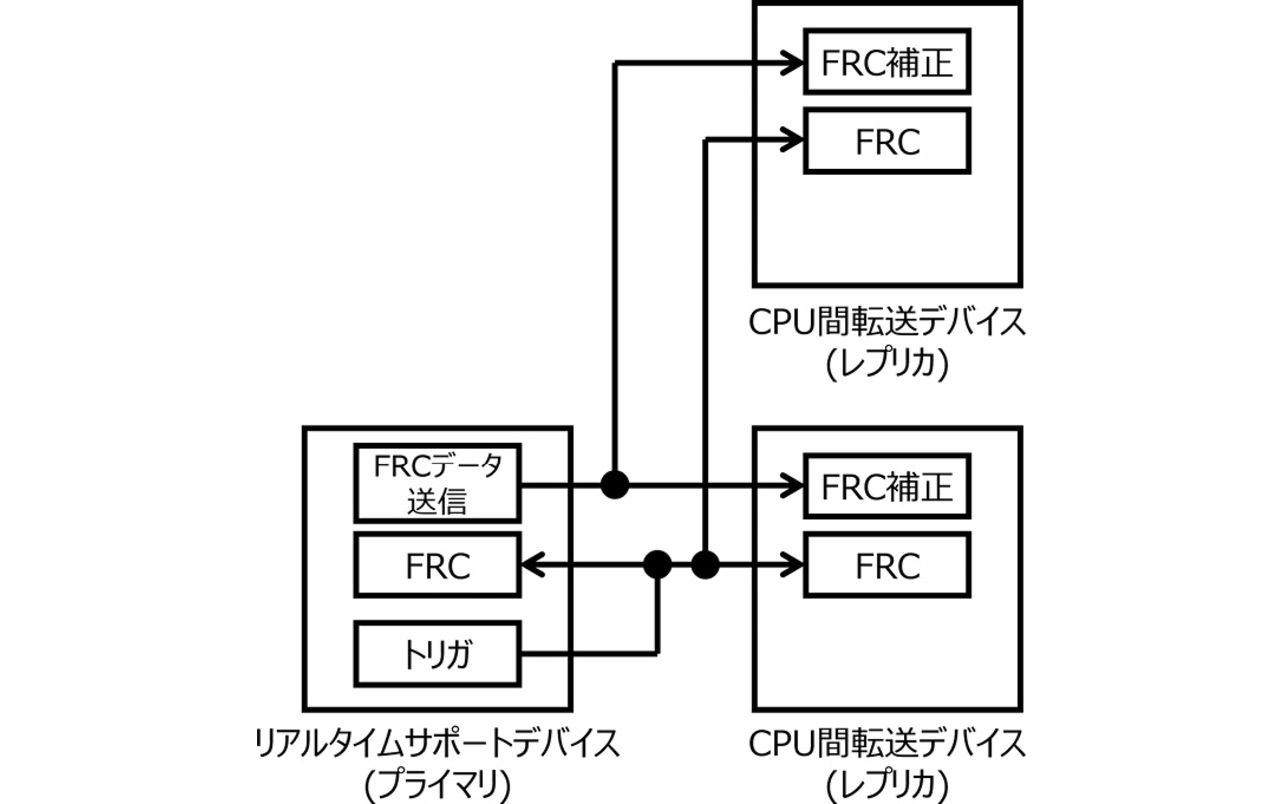
図8に時刻補正のタイミング図を示す。最初にプライマリはトリガを発行する。プライマリ/レプリカはそれぞれ、トリガ受信時のFRC値を保存する。次にプライマリはその保存したFRC値をレプリカに伝送する。レプリカはプライマリからのFRC値と自身が保存しているFRC値とを比較し、その差分をレプリカのFRCに対して補正処理を実行する。これらにより、FWを使用せずHWのみの実装で時刻同期を実現することができる。

5. 本提案手法の効果
前章で提案した高速な時刻同期を行うために、本章ではHWを用いた時刻同期の実機確認を行い、その結果を図9、図10に示す。
時刻同期実施後、プライマリとレプリカの時刻のずれ幅の大きさは補正処理によっても変わるが、ずれ幅に対して最も影響する要素が補正周期である。そこで、実機確認では補正周期を8ミリ秒と250マイクロ秒で比較した。
本実機確認で採用した補正処理について説明する。時刻同期におけるレプリカ側での補正処理の実装は様々ある。もっとも単純にはレプリカ側が認識したプライマリ側のFRC値をそのままレプリカ側にコピーするなどの方法があるが、それではFRC値が大きく変化する場合があり、FRCを使用しているタイマへの影響が出てしまう。そこで、レプリカ側のFRC値を少しずつ早める、または遅くするなどの補正処理を行うのが一般的である。今回の補正処理では、補正周期が8ミリ秒の場合は70マイクロ秒毎に1ナノ秒の補正、補正周期が250マイクロ秒の場合は1マイクロ秒毎に1ナノ秒の補正を実施することとし、最大100ナノ秒の補正を行える回路とした。
5.1 HWを用いた時刻同期手法の実機確認
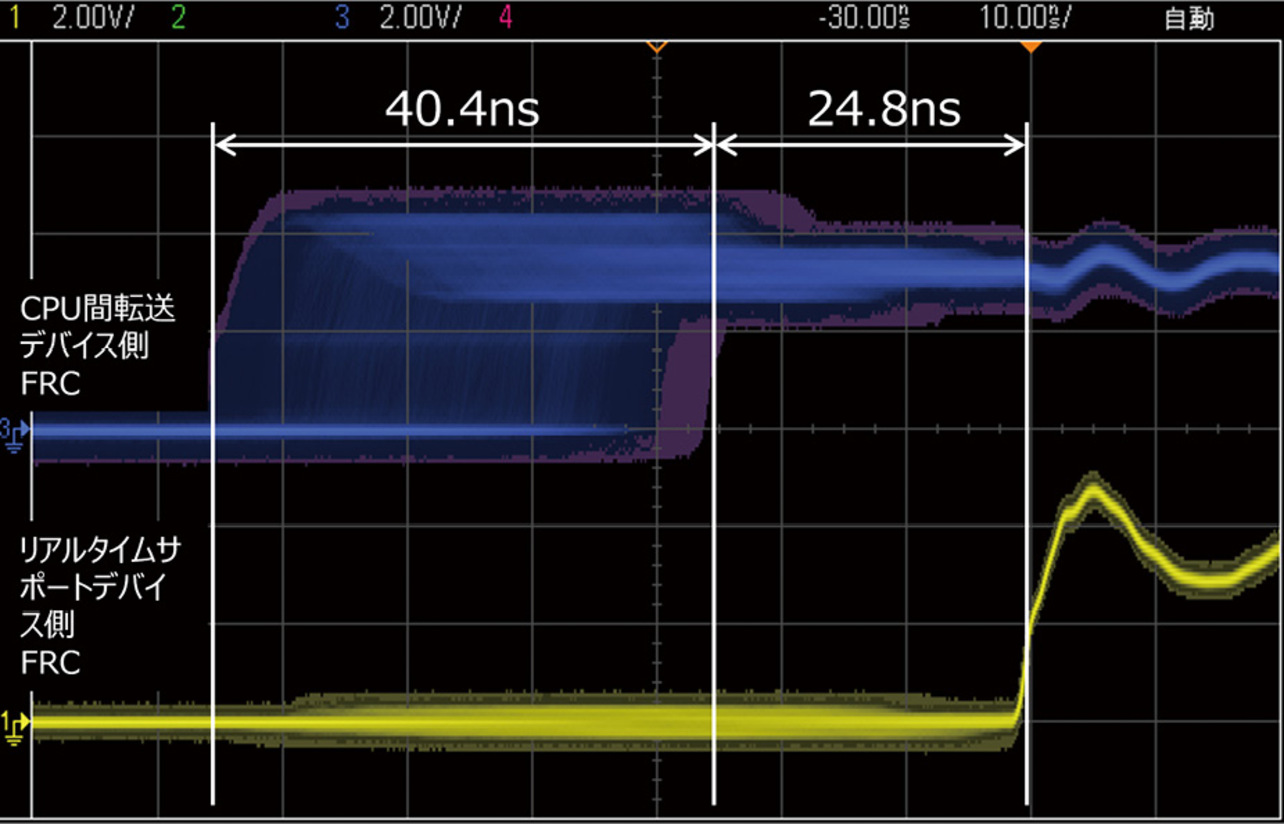
前章で提案したHWを用いた時刻同期を実施した結果を図9に示す。図9では図2において、リアルタイムサポートデバイス側とCPU間転送デバイス側のFRCの一部のビットをオシロスコープにて観測した波形である。リアルタイムサポートデバイス側の波形の立ち上がりをトリガにしCPU側転送デバイスの波形を観測したものである。図9ではHWにて8ミリ秒に一度補正処理を実行しており、補正元である制御用CPU側のFRCと比較して、-65.2ナノ秒~-24.8ナノ秒(センター:-45.0ナノ秒)の精度となっている。FRC値の補正する際は徐々にFRC値を増減していく手法を採用しているため、トリガ発生のタイミングからFRC値の補正が完了するまでには時間がかかる。そのため、FRC値の補正が完了した段階においては、トリガ発生時に発生していたFRC値のずれ量の補正が完了しているが、補正完了までにかかる時間の間にFRCずれが発生しており、そのずれが24.8ナノ秒という形で見えていると考える。また、FRCの補正が完了してから次の補正が開始されるまでの8ミリ秒の間に40.4ナノ秒のFRCずれが発生したと考えられる。
本手法によって、HWで問題なく時刻同期が実現できることがわかった。8ミリ秒で時刻同期する場合、理論上最大400ナノ秒の偏差が出る可能性があったが、今回実験に用いた発振器の精度、温度等の条件が比較的良く、時刻のずれ幅の大きさについては約65ナノ秒が観測されている。
5.2 HWによる時刻補正周期短縮化の効果
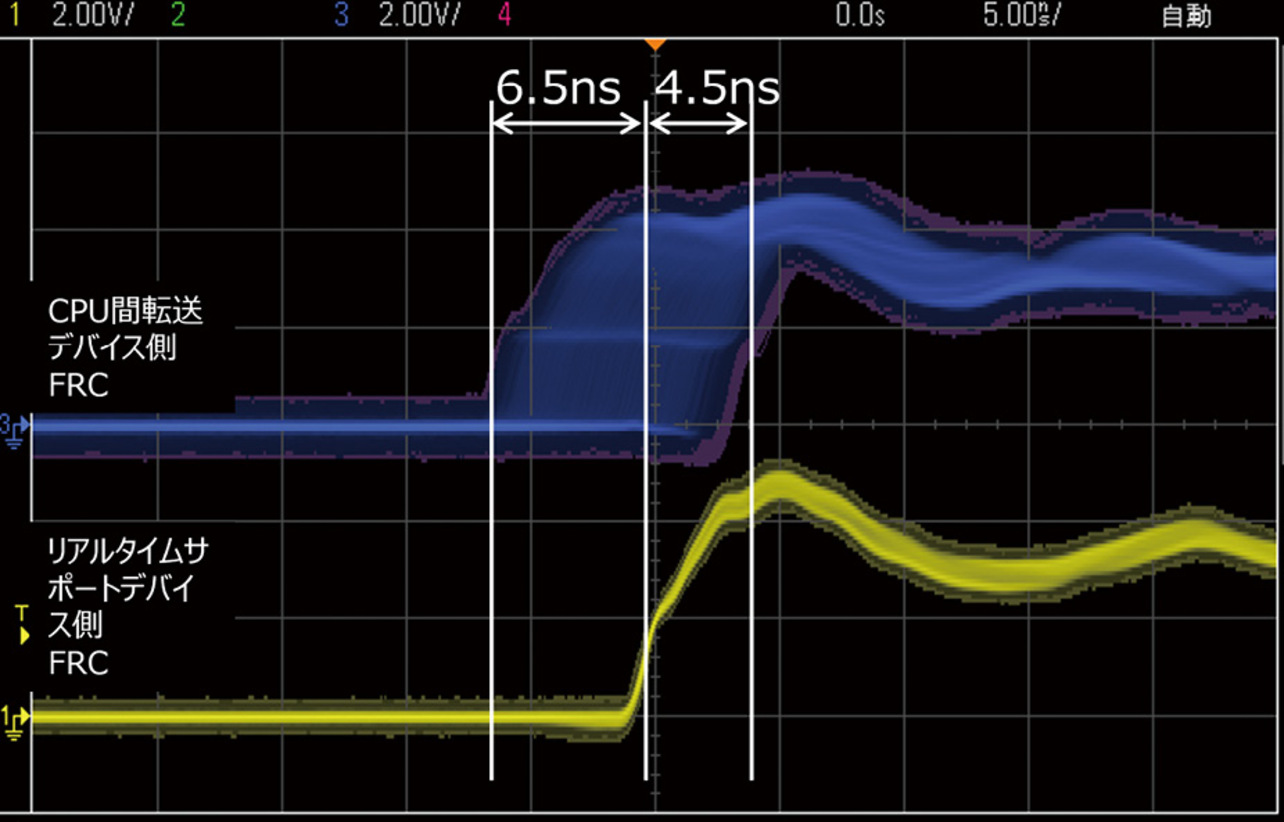
HWで高精度な時刻同期を実現するため、高頻度に時刻補正を実施した結果を図10に示す。HWで補正するようにしたため、250マイクロ秒という高速な補正周期を実現することができた。その同期精度は-6.5ナノ秒~+4.5ナノ秒(センター:-1.0ナノ秒)となっており、8ミリ秒間隔の補正よりも大幅に同期精度が向上している。
今回実験に使用したタイマデバイス内部のクロック周期は8ナノ秒であり、トリガ信号は8ナノ秒のクロックでラッチされる。トリガ信号とクロックとは非同期であるため、トリガ信号をラッチするタイミングによって±8ナノ秒の時刻同期誤差は発生する。そのため、図10においてリアルタイムサポートデバイスよりもCPU間転送デバイスの方が最大+4.5ナノ秒進んだ状態が観測されたものと考えられる。
補正周期を短くすることで、FRC値の同期精度を大幅に改善することが実機評価でも確認でき、目標である39ナノ秒以下である11ナノ秒の同期精度を実現することができた。
このHWによる時刻同期技術によって、リアルタイムサポートデバイスとCPU間転送デバイスのFRC値が高精度に同期することができるため、DMA転送マスク機能を高精度に機能させることができる。DMA転送マスクはCPU間転送デバイスごとに設定することができるため、複数のCPU間転送デバイスからのDMA転送においてもメモリ競合なくDMA転送することができ、リアルタイムシステムへの影響を最小限に抑えることができる。
6. むすび
本稿ではリアルタイムシステムにPCIeを適用するために必要な技術について論説した。コントローラの進化の一形態として分散型リアルタイムシステム構成を示した。分散型リアルタイムシステムでは複数のPCIeデバイスからのDMA転送によってリアルタイム性能への影響が発生するといった課題に対し、DMA転送マスク機能によるリアルタイム処理中のDMA転送を抑制する仕組みを提案した。DMA転送マスク機能を効果的に機能させるためにはリアルタイムサポートデバイスとCPU間転送デバイスの各タイマデバイスのタイマ値を同期させてDMA転送タイミングを高精度に同期させるといった新たな課題が発生した。これに対してHWによる時刻同期技術を新たに提案し、高頻度に時刻同期を実施することにより、時刻同期の目標値を達成することができた。
今後においても、リアルタイムシステムにPCIeデバイスが活用されていくことが予想される。特にTime Sensitive Network(TSN)など、コントローラは外部機器とのリアルタイム性を維持した接続が求められていくと考える。コントローラにとって時刻同期はリアルタイムシステムとして重要な要素となり、コントローラ内の時刻同期精度が外部機器との同期精度とも密接に関係している。本稿で提案した時刻同期技術は今後、外部機器と高精度に時刻同期するために重要な技術となる。
参考文献
- 1)
- オムロン株式会社. マシンオートメーションコントローラ NJ/NXシリーズ, 第AH版.(2025). Accessed: Feb. 17, 2025.[Online]. Available: https://www.fa.omron.co.jp/data_pdf/cat/nj_nx_sbca-100_14_2.pdf
- 2)
- PCI-SIG, PCI Express Base Specification Revision 2.1, 2009.
- 3)
- オムロン株式会社, “転送装置、情報処理装置、および、データ転送方式,” 特許第7326863号, Aug. 7, 2023.
- 4)
- オムロン株式会社, “情報処理装置,” 特許第7259537号, Apr. 10, 2023.
- 5)
- オムロン株式会社, “制御装置,” 特開2022-119703, Aug. 17, 2022.
本文に掲載の商品の名称は、各社が商標としている場合があります。
PCIe, PCI ExpressはPCI-SIGの登録商標です。
Ethernetは富士フィルムビジネスイノベーション株式会社の登録商標です。