














良品生産性向上のためのQ-upSystemを支えるデータ収集・分析基盤の開発
- データ分析基盤
- SMT
- はんだ検査装置
- データウェアハウス
- データマート
検査システム事業部では、従来からプリント実装基板を3D計測し、定量化された品質基準に従って検査を行うAOI (Automated Optical Inspection)、3D-CT方式ではんだの形状の検査を行うAXI (Automated X-ray Inspection)、各工程検査装置からの品質データや生産情報を分析するQ-upNavi、不良を作らない生産作りに貢献するためにマウンタと連携するQ-upAutoを開発しており、多くの生産現場で、不良流出防止や品質維持改善に貢献している。
Q-upAuto とQ-upNaviで構成するQ-upSystemは、扱うデータや処理を追加しながら開発を進めており、段階的な機能拡張を生産現場に適用するためには、高速なサーバを使用せずに機能を実現する基盤が必要となる。
今回、ビックデータのようなデータ分析基盤の構築方法を元に、製造データと品質データの紐づけ・蓄積・分析の知見を加えたQ-upSystemのデータ収集・分析基盤を開発した。最終工程の品質データを起点に前工程の検査基準を最適化する機能用のデータ検索・取得の性能評価を行い、高速なサーバを導入することなく十分な高速性を得られた。
1. まえがき
近年、自動車の安全設備やハイブリッド車の普及が急速に進み、自動車に搭載される電子部品基板が急速に増加しており、将来の自動運転に向けて、より高度化される見込みである。自動車に搭載される部品には高い品質が求められるため、プリント実装基板の実装ラインは不良を流出させないだけでなく、手直しで良品とすることも禁じられる場合があり、不良を作らないことが必要になっている。
また、豊富な経験と知識を持つ熟練した実装ライン担当者、製造技術者の高齢化が進み、高い品質を達成し維持する人材がこの10年に渡り減少し続けている。そういった人材が確保できている現場においても、コスト競争力が求められるため、改善に多くの工数を使うことができない。また業界のグローバル化が進み、高い品質を達成し維持する人材がいない拠点でも、高い品質を達成することが求められている。
従来より、検査システム事業部では変動する生産の4M「Man(作業者)」「Machine(機械設備)」「Material(原材料)」「 Method(作業方法)」に対応し、良品を作り続けるために検査装置の品質データを起点に、各設備データの紐づけ⇒収集⇒監視⇒改善を自動で実行するQ-upSystem(図1)を開発し、顧客の品質改善・維持とコスト競争力への貢献を目指している。Q-upSystemは、検査装置の品質データと生産設備(印刷機・マウンタなど)の製造データを紐づけし、リアルタイムに異常を警告するQ-upAuto1)、各工程検査装置からの品質データや生産情報を分析するQ-upNaviで構成される。
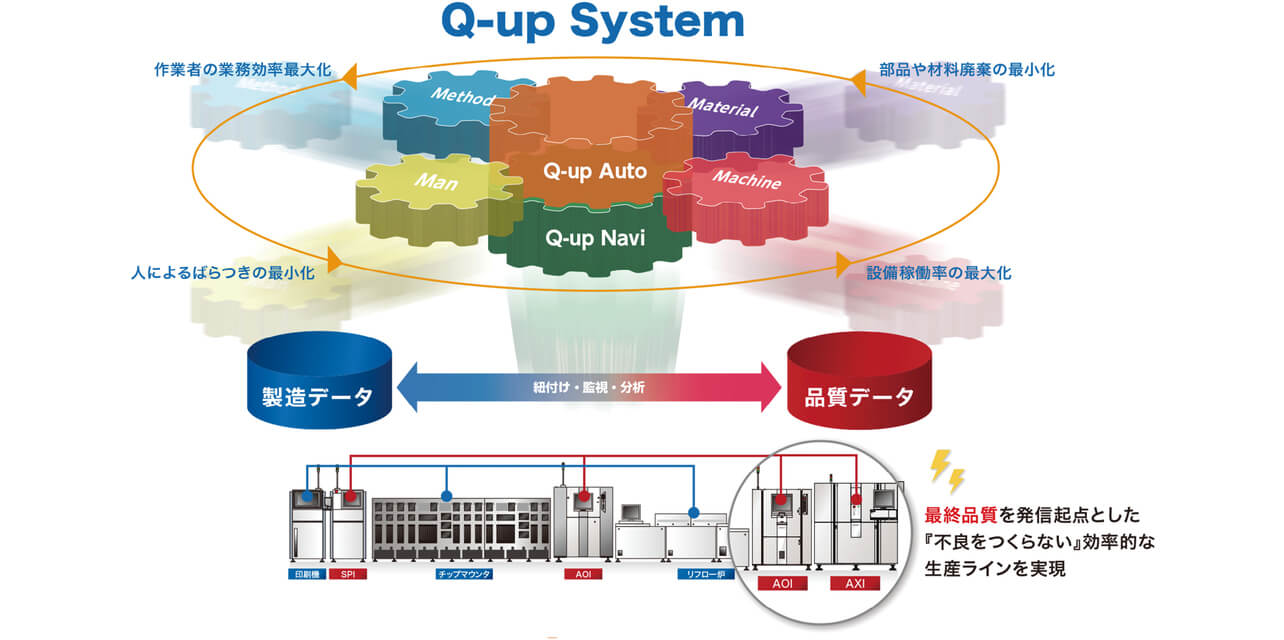
Q-upSystemは、品質改善の機能を提供するアプリケーション部と検査装置の品質データ、生産設備の製造データを収集しアプリケーションに提供するデータ収集・分析基盤で構成される。アプリケーションは、リアルタイムに品質の変動を捉えて品質改善を行うために、大量のデータを基にした自動分析を行う必要があり、データ収集・分析基盤は、高速なデータの紐づけとアプリケーションから指定された条件のデータを紐づけた状態で高速に収集することが必要となる。
実装基板の実装工程では、生産ライン数は最大で100ライン程度であり、サイクルタイム(10秒~1分程度)毎に製造データ、品質データが生成される。現在のQ-upAutoでは、マウンタの製造データと検査装置からの製造データを基板1枚毎に収集して、基板1枚毎のファイルとして保存し、基板1枚毎に紐づけを行っている。品質データには、大量の計測値があるため、1ライン分のマウンタの製造データと品質データは1日に1GB 程度であり、90%以上は計測値の数値データとなる。現在、1台のサーバで3ライン分のデータ収集と紐づけは可能であるが、ファイルの入出力が多いために4ライン以上の処理が難しく、4ライン以上の顧客への適用ができないため、データの格納方法を改善する必要がある。また、現在のQ-upNaviでは、複数の検査工程の検査結果・計測値を取得できるが、計測値を基板1枚毎のファイルとして保存しているため、複数の基板の計測値を取得する場合に時間がかかるため、リアルタイムな自動分析機能の開発に利用できない問題がある。
近年のビックデータのようなデータ分析基盤はデータウェアハウス2)を含む表1に示す三層のデータレイヤーで構成し、BI(Business Intelligence)で意思決定を支援することが多い。これらはリレーショナルデータベースやNoSQLデータベースを用い、オンプレミスの高価なサーバ上、または、クラウド上で構築することが多い。これらの技術は様々な分野で適用されているが、先に述べたように実装基板の実装工程では、製造データと品質データの紐づけ・蓄積・分析の知見が必要なこと、および、ネットワークをクラウドに接続することや高価なサーバを用いることが難しいため、適用されている事例はない。
| データリポジトリ | 説明 |
|---|---|
| データレイク | データソースとなるシステムやデータベースから収集してきたデータをそのままの形で保存するもの。データソースから分離することで、再収集が必要な場合にデータソースへの影響をなくすことができる。 |
| データウェア ハウス |
データソースやデータレイクから収集したデータを分析のために、目的別に編成され、統合された時系列で、削除や更新しないデータの集合体。 |
| データマート | データウェアハウスの中から特定の目的に合わせた部分を取り出し、活用に適した形に加工したデータを保持する。 |
本稿では、大量のデータの収集と紐づけ、および、自動検知、分析のために品質データを高速に検索・取得するQ-upSystemを支えるデータ収集・分析基盤の構築方法について紹介する。実装基板の実装工程のデータの特性と自動分析に適したデータ設計について述べ、構築したデータ収集・分析基盤の基本性能について述べる。
2. データ収集・分析基盤の課題
2.1 プリント実装基板の実装工程のデータ
プリント実装基板の実装工程は、次のように構成される。先頭から、はんだ印刷機、SPI、マウンタ、マウント後AOI、リフロ炉、リフロ後AOI、AXIが並ぶ。それらの装置は図2の上部のように一直線で配置され、上流から下流(この図の場合左から右)にプリント配線板(以降基板と呼ぶ)を流しながら実装を行う。はんだ印刷機は基板にステンシル状の金属板を介してはんだを印刷し、SPI は印刷されたはんだの印刷状態を検査する。マウンタはそのはんだの上に電子部品を搭載し、マウント後AOIはその部品の搭載状態を検査する。リフロ炉は部品を実装した基板を加熱してはんだを溶融させ、基板を冷却させることではんだを硬化させて電子部品を基板に固定する。リフロ後AOIとAXIは、このようにして実装された完成品を検査する。
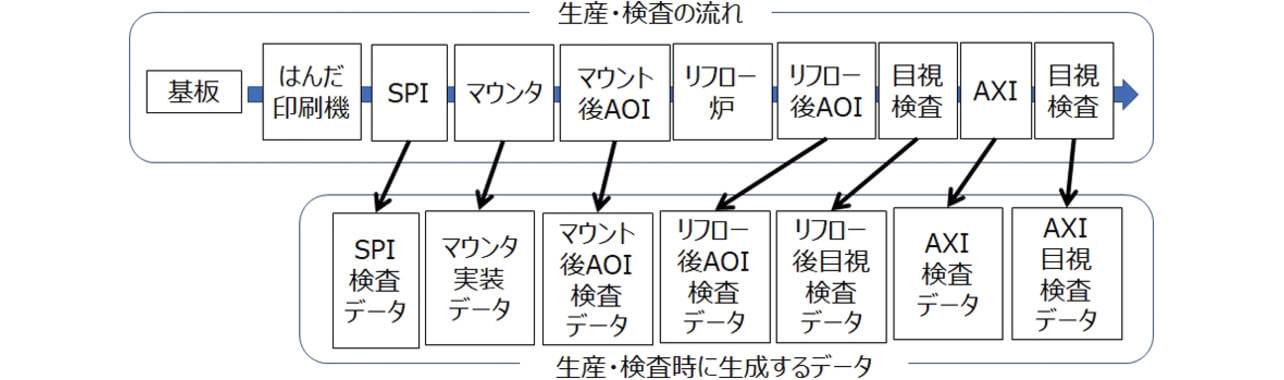
基板には図3のようにトレーサビリティ用に基板IDが刻印されており、一つまたは複数の個片基板がある。個片内の回路番号の場所に電子部品が搭載され、電子部品のピンがはんだにより基板に固定されている。図2に示すように、生産・検査後に各データが生成される。検査装置でNG判定された場合のみ、目視検査を行い、NG判定した回路の部品、ピンの目視検査結果データが生成される。
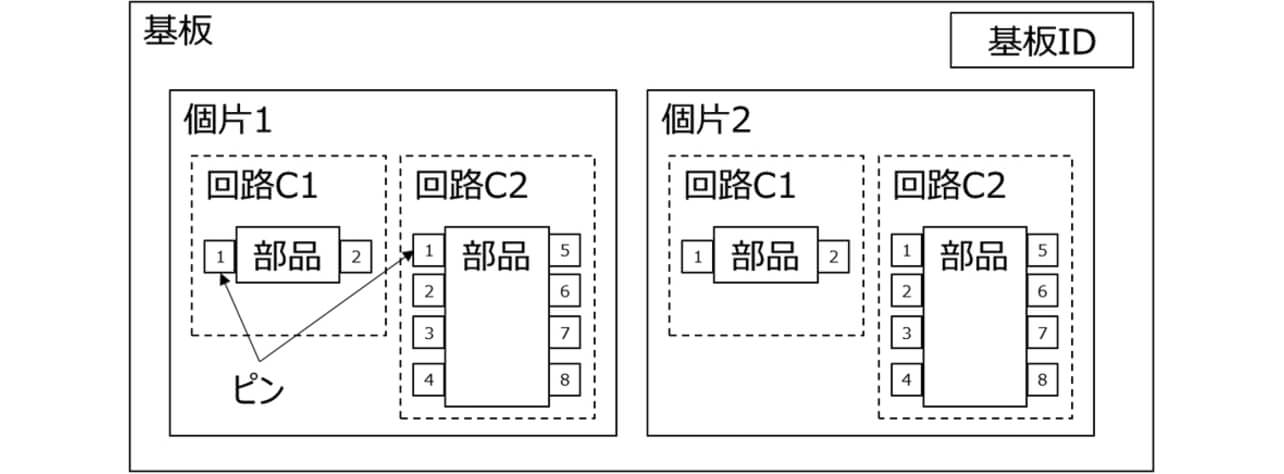
表2に基板サイズ236 mm×154 mm、総部品数が938個、総ピン数が2,692個の基板1枚当たりの品質データ量を示す。検査結果の数は、総部品数と総ピン数と同数であり、計測値の数はSPIが29,612個、マウント後AOIが132,122個、リフロ後AOIが157,464個となる。
| 項目 | SPI | マウント後AOI | リフロ後 AOI |
|---|---|---|---|
| 検査結果数(部品) | ― | 938 | |
| 検査結果数(ピン) | 2,692 | ||
| 計測値数 | 29,612 | 132,122 | 157,464 |
2.2 データ収集・分析基盤の課題
Q-upSystemのアプリケーションは、機能毎にリアルタイムや1日に1~24回などの周期、または、ユーザによるトリガでデータ収集・分析・監視を行い、条件を満たした場合に、追加のデータ収集・分析や、改善の処理を実行する。Q-upSystemの特徴は、品質データを起点に上記の処理を行うことであり、データ収集・分析基盤に対する課題は下記になる。
課題1:
製造データ、品質データをプリント実装基板の実装ラインのサイクルタイム内(10秒~1分程度)で紐づけること。
課題2:
品質データを高速に検索・取得できるようにデータを格納し、アプリケーションが利用しやすい形に変換すること。
課題3:
生産ライン数(最大100ライン程度)に対応できるスケーラビリティがあり、工場内のオンプレミスのシステムとして、高価なサーバを使用せずにシステムを構築できること。
課題1は基板1枚毎の製造データと品質データの紐づけ処理性能面の課題である。例として、表3にQ-upAutoの不良通知機能を示す。表3のデータ収集・分析基盤機能では、表2の基板をサイクルタイム30秒で生産する場合、938個の部品を搭載した製造データと3つの検査工程の検査結果を30秒以内に紐づける必要がある。
| 項目 | 内容 |
|---|---|
| アプリ機能 | 発生した実不良を実装したマウンタデバイスIDをUIに表示する。 |
| データ収集・分析基盤機能 | 発生した実不良を実装したマウンタデバイスIDをリアルタイムに集計する。 |
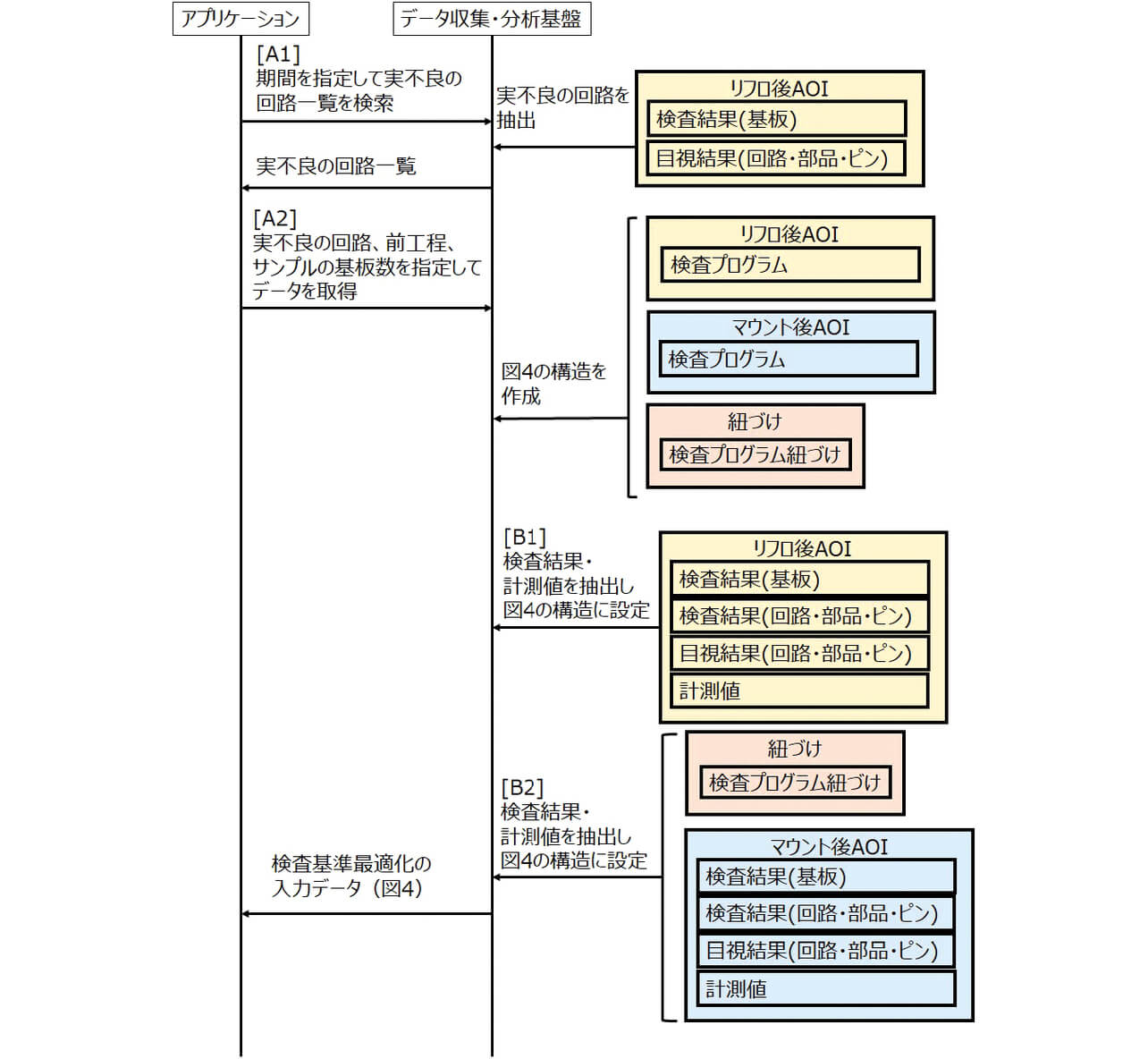
課題2は品質データの検索性能に関する課題である。格納している大量の品質データの中から、効率的に検索・取得できる必要がある。例として、表4にQ-upOpti(2021年販売)の検査基準最適化機能を示す。課題2は、表4のレスポンス確保のために必要なものである。表4の前工程の検査基準の最適化の計算のためには、計算に必要なサンプル数となる10~200枚程度の基板、部品の検査結果と計測値、および、検査基準が必要になる。検査基準の最適化計算では、同一の基板・部品の複数工程の検査結果・計測値と現在の検査基準を考慮するため、図4に示す入力データ構造が必要となる。例えば、10日分の1ラインの製造データと品質データ(約10GB)の中から、リフト後の部品の検査結果に関連する品質データ(約10MB)を抽出し、同一部品のデータとして紐づけた形に10秒以内に変換することである。
| 項目 | 内容 |
|---|---|
| アプリ機能 | リフロ後検査で実不良を検知した際、前工程の検査(SPIまたはマウント後AOI)で検知すべき不良の場合に、計測値を元に前工程の検査基準の最適値を計算し、検査基準を変更する。 |
| データ収集・分析基盤機能 | アプリから指定された実不良の部品品番と同じリフロ後の検査基準の計算に必要な数の良品と不良の計測値と検査基準、および同じ基板の前工程の部品の計測値と検査基準を返す。 |
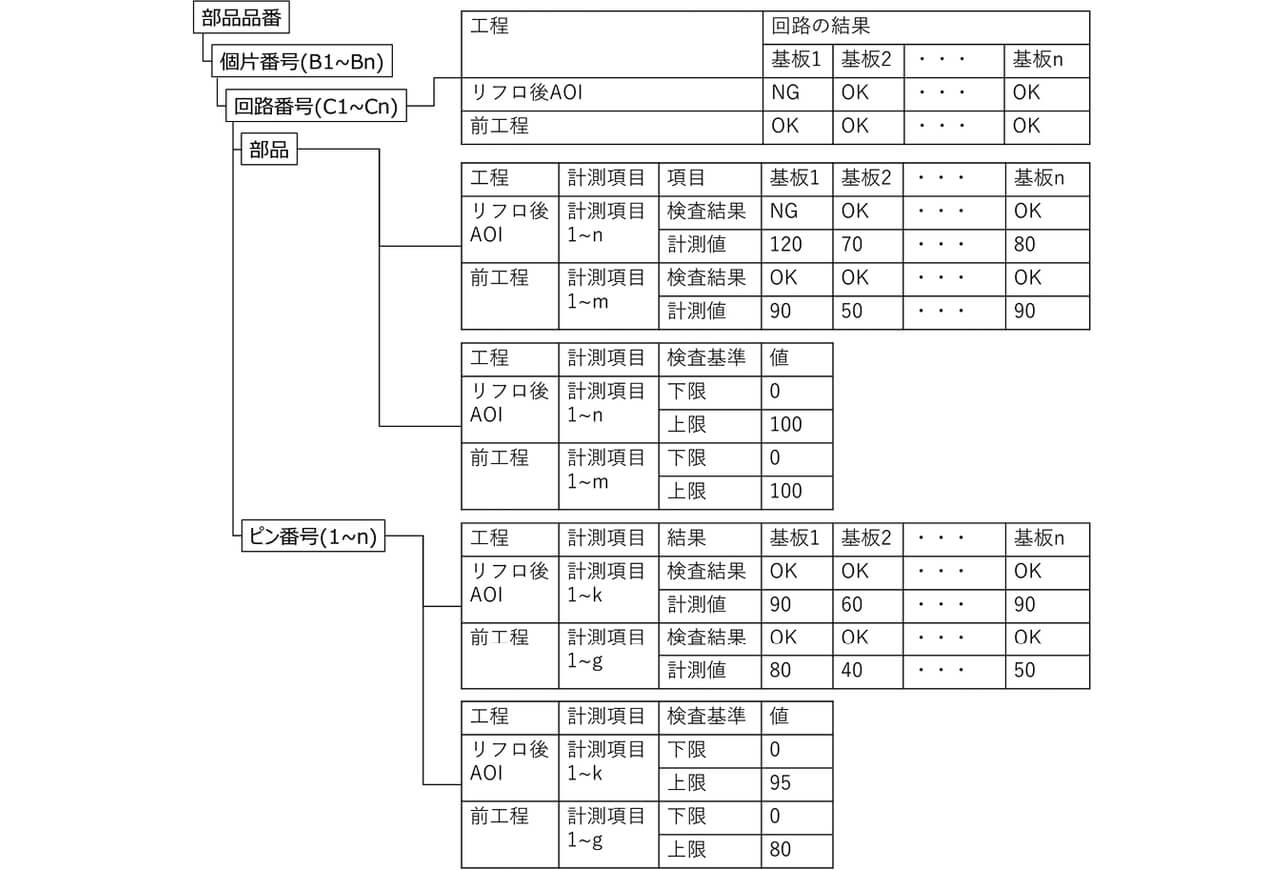
課題3は、適切なコストでQ-upSystemを導入するために必要な課題である。顧客毎に生産ライン数やネットワーク構成も異なるため、多様な構成に対応できる必要がある。
次節では、これらの課題に対する解決方法について述べる。
3. データ収集・分析基盤の設計
2.2節の課題1の解決のために、同一テーブルへのデータの同時書込みによる不整合を回避するためのロック待ちによるレスポンス低下を避けることが必要である。そこで複数の実装ラインの装置からのデータの入力に対して、データテーブルを装置毎に分割し、データをロックする範囲は装置毎に限定する。データの紐づけ処理は、装置毎に保存されたデータを入力として、実装ライン毎に独立して行うことでレスポンスを確保する。
2.2節の課題2の解決のために、データの検索・取得時に、サーバのディスクI/Oを減らすようにアクセスするデータの範囲を局所化することが必要である。そこでデータのアクセスパターンとデータ量に応じて、データテーブルの種類と期間の分割を適切に設計する。品質データの基本取得パターンは、「期間と品質の条件を指定して検索し、検索結果に基づき、関連するデータや詳細データを取得する」となる。基本パターンの例として、表4の検査基準最適化機能のための検査基準最適化計算の入力データの取得シーケンスを図5に示す。図5は前工程がマウント後AOIの場合を表している。アプリケーションは、「[A1]期間を指定して実不良の回路一覧を検索」した後に、「[A2]実不良の回路、前工程、サンプルの基板数を指定してデータを取得」する。この時、アプリケーションが取得するデータ量の90%以上は「計測値」であるため、「[B1][B2]検査結果・計測値を抽出し図4の構造に設定」の中の計測値の抽出と設定に最も時間がかかる。この基本パターンを元に、検査結果のテーブルを「検査結果(基板)」「検査結果(回路・部品・ピン)」「計測値」とし、利用頻度とデータ量を考慮して、1テーブル内の期間をそれぞれ、1日、1時間、10分とする。また、「計測値」は部品品番毎に取得・分析するため、部品品番毎に分割する。上記の分割をすることで、検索・取得時のアクセスするデータの範囲を局所化でき、高いレスポンスが期待できる。
2.2節の課題3に関しては、データを検査装置、期間で分割することにより、データの分散配置が可能となり、スケールアウト(コンピュータの台数を増やすことでシステム全体の性能を向上させること)が容易になる。これにより生産ラインを段階的な置き換えや増設時に段階的に安価なサーバを増やすことや、システム規模に応じたサーバ選定が可能となる。
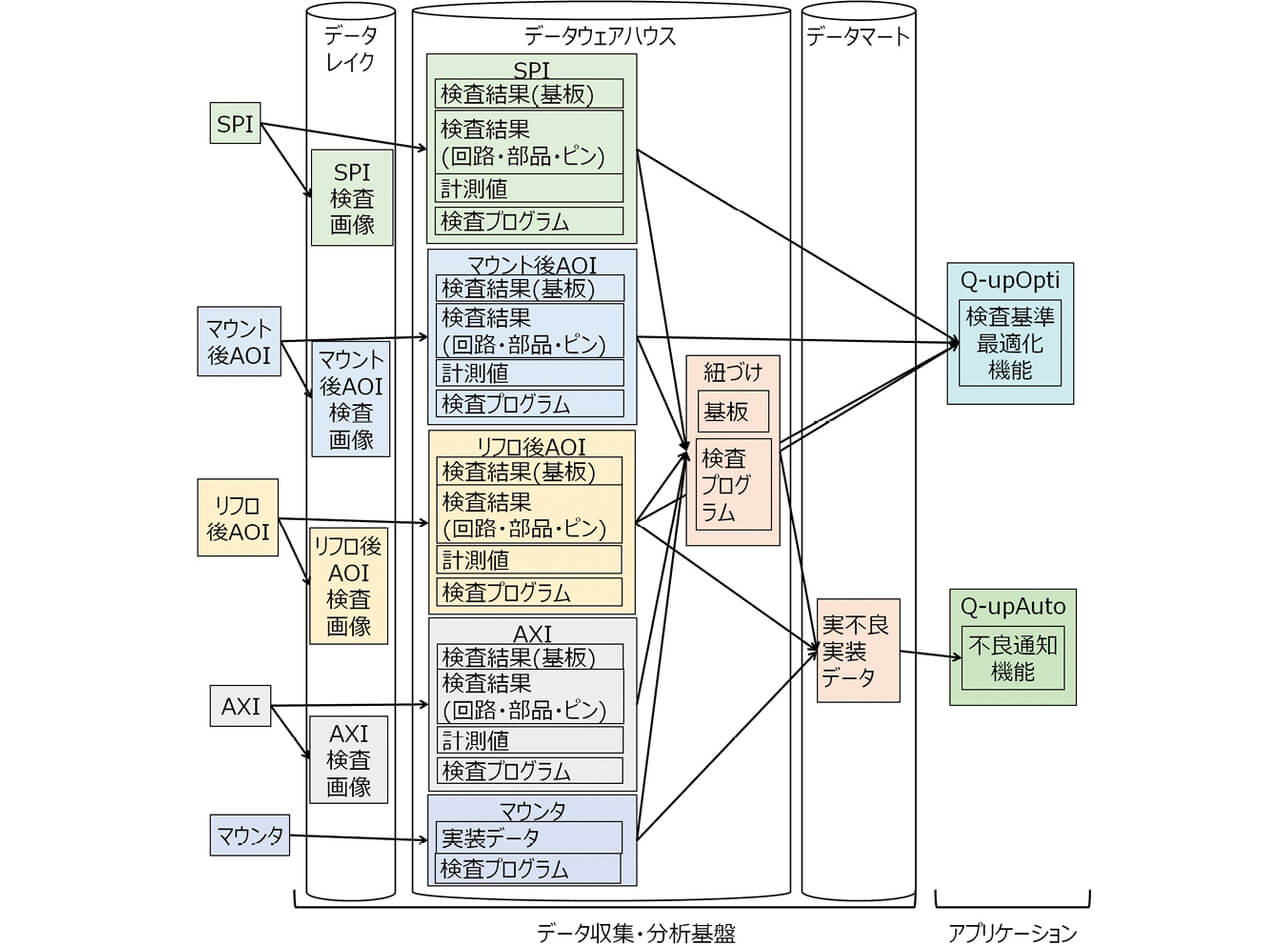
以上を考慮して、表1のデータレイヤーを適用したデータ収集・分析基盤の構成を図6に示す。図内の矢印はデータの流れを表している。データレイクには、アプリケーションが必要とした検査画像を検査装置から取得した後に配置し、検査装置からの複数回の取得を回避する。データウェアハウスには、検査装置(SPI、マウント後AOI、リフロ後AOI、AXI)の品質データ(検査結果、検査プログラム)と生産設備(マウンタ)の実装データと各工程の紐づけデータを配置する。データマートには、アプリケーションが表3の不良通知機能でそのまま利用できる実不良の部品を実装したマウンタデバイスIDのリスト「実不良実装データ」を配置する。
4. 性能評価
4.1 性能評価1
本節では、データ量が多く高速化の難易度が高い2.2節の課題の検証のために、高価でないサーバでファイルベースのシステムをC#で実装し、課題1を対象とした紐づけ速度の性能評価(以降性能評価1と呼ぶ)を行った結果を述べる。性能評価1では、弊社工場の5時間分の生産データの中から、マウンタと検査装置2台分のデータに対して、検査不良データの紐づけ時間の評価を行う。
性能評価1の結果を表5に示す。表5より、1基板あたりの紐づけ時間は13.3 msとなり、実装ラインのサイクルタイム(10秒~1分程度)より、十分小さい時間となった。これは、「検査結果(回路・部品・ピン)」のテーブルを1時間単位にすることで、データの紐付け時のI/Oを局所化していることが大きな要因である。
| ケース | 紐づけ部品数 (検査不良部品) |
検査枚数 | 紐づけ時間[ms] |
|---|---|---|---|
| 1 | 116 | 148 | 1559 |
| 2 | 188 | 163 | 1873 |
| 3 | 206 | 191 | 1927 |
| 4 | 191 | 96 | 2274 |
| 5 | 72 | 41 | 839 |
| 合計 | 773 | 639 | 8,472 |
| 1部品あたりの紐付け時間[ms] | 11.0 | ||
| 1基板あたりの紐付け時間[ms] | 13.3 | ||
4.2 性能評価2, 3
本節では表4の検査基準最適化機能を対象としたデータの取得速度の性能評価(以降性能評価2と呼ぶ)を行った結果を述べる。また、性能評価2の比較のために従来のQ-upNaviで計測値の取得速度の性能評価(以降性能評価3と呼ぶ)を行う。性能評価2では、2つの工程の計測値を取得するが、Q-upNaviには、複数工程の計測値を紐づけて取得する機能はないため、2つの工程の計測値の取得時間を、1つの工程の計測値の取得時間を2倍して性能比較を行う。
性能評価2、3では、938個の部品を搭載した基板のデータを用いた。性能評価2では、表6のデータに対して、基板10、20、50、100、200枚のリフロ後AOIとマウント後AOIのデータを取得し、図4の構造に変換するまでの時間を計測した。性能評価3では、表6のデータに対して、基板10、20、50、100、200枚のリフロ後AOIの計測値のデータを取得し、2倍の時間を2工程分のデータ取得時間とした。性能評価1、2に使用したPCのスペックは、OS:Windows 10、CPU:Intel® Core i7-6600U@2.60GHz、メモリ:16GB、ストレージ:SSDのノートPCであり、性能評価3では商品の標準スペックのサーバ(OS:Windows Server 2016、CPU:Intel® Xeon® E5-2630 v4@2.40GHz、メモリ:16GB、ストレージ:SAS 10,000RPM)を使用した。
| 名称 | 部品種 | ピン数 | 基板上の部品数 |
|---|---|---|---|
| 部品品番A | チップ抵抗 | 2 | 40 |
| 部品品番B | SOP | 8 | 4 |
| 部品品番C | QFP | 208 | 2 |
性能評価2の結果を図7と表7、性能評価3の結果を図8と表8に示す。性能評価2と性能評価3の速度比較を表9に示す。表9より、性能評価2の時間は、性能評価3の時間より基板枚数10枚で19.7倍以上短縮され、基板枚数が増えるにつれ高速化の効果が大きくなるなど、従来と比べ大幅な高速化ができた。これは、計測値のテーブルを部品品番と期間で分割することにより、データ取得時のI/Oを局所化していることが大きな要因となったためである。従来のシステムは計測値を除くデータを検査装置毎に分割せずに、リレーショナルデータベースのテーブルに格納し、計測値のデータは、基板1枚毎のファイルに格納していたため、複数の基板の計測値を取得する場合にI/Oが多くなり、時間がかかっていた。
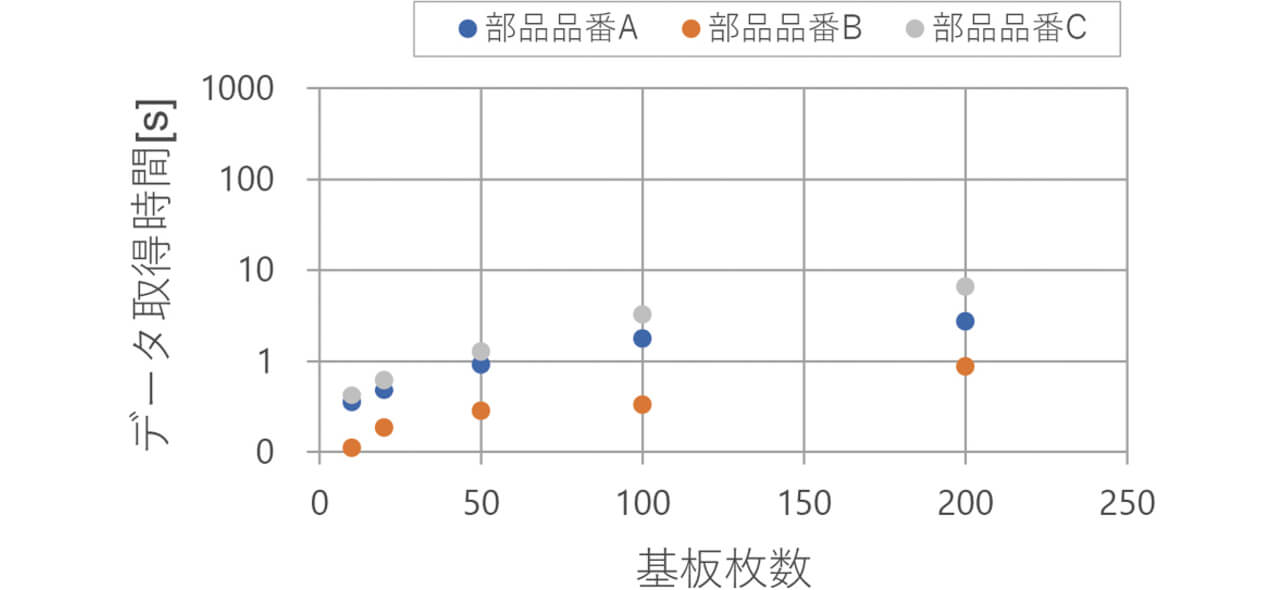
| 基板枚数 | 取得時間[s] | ||
|---|---|---|---|
| 部品品番A | 部品品番B | 部品品番C | |
| 10 | 0.35 | 0.11 | 0.42 |
| 20 | 0.48 | 0.18 | 0.63 |
| 50 | 0.92 | 0.28 | 1.28 |
| 100 | 1.79 | 0.33 | 3.26 |
| 200 | 2.75 | 0.88 | 6.59 |
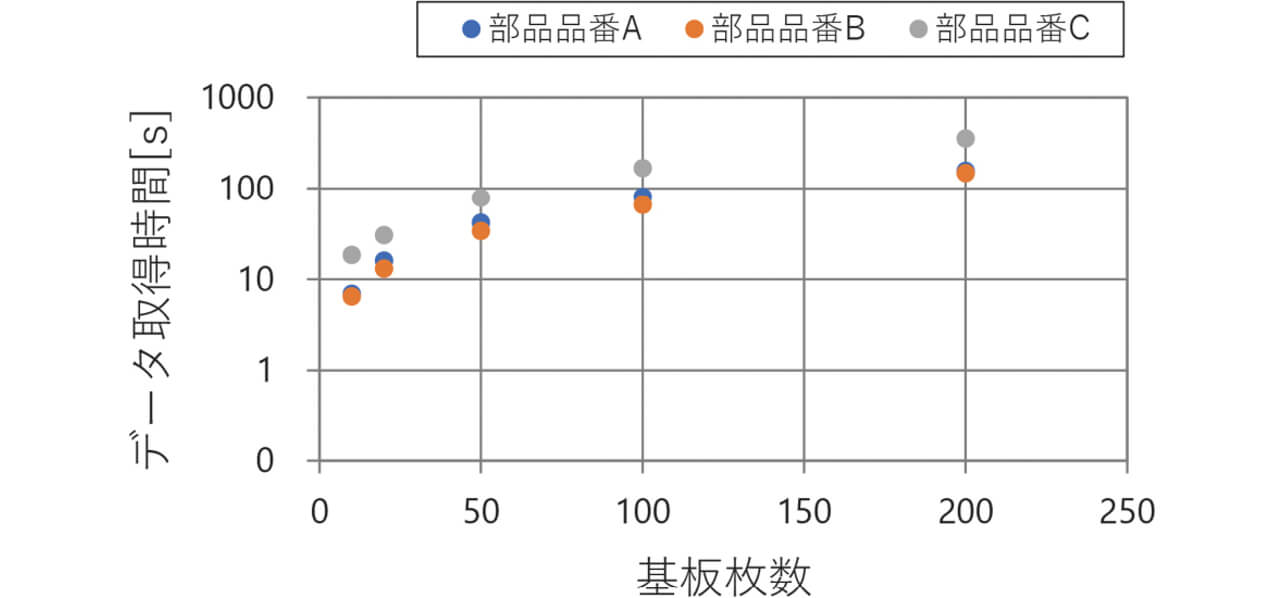
| 基板枚数 | 取得時間[s] | ||
|---|---|---|---|
| 部品品番A | 部品品番B | 部品品番C | |
| 10 | 6.94 | 6.49 | 18.5 |
| 20 | 15.93 | 13.1 | 30.3 |
| 50 | 41.72 | 33.69 | 78.89 |
| 100 | 81.12 | 65.66 | 168.97 |
| 200 | 156.96 | 148.93 | 356.79 |
| 基板枚数 | 取得時間の比率 (性能評価2の時間/性能評価3の時間) |
||
|---|---|---|---|
| 部品品番A | 部品品番B | 部品品番C | |
| 10 | 19.7 | 58.7 | 44.0 |
| 20 | 33.3 | 71.2 | 48.4 |
| 50 | 45.1 | 119.7 | 61.4 |
| 100 | 45.4 | 200.2 | 51.9 |
| 200 | 57.2 | 169.3 | 54.2 |
5.むすび
製造データ、品質データのリアルタイムの紐づけと高速な検索取得を高価なサーバを使用せずに実現する課題に対して、データのアクセスパターンとデータ量に応じたデータテーブルの種類と期間の分割を適切に設計したデータ収集・分析基盤を開発した。最終工程の品質データを起点に前工程の検査基準を最適化する機能に向けた性能評価を行い、高速なサーバを導入することなく十分な高速性を得られた。本基盤は、2021年に販売したQ-upOptiを支える基盤となっている。
今後は、現在のQ-upAutoの対応ライン数の拡張のために、2.2節の課題1の解決方法の適用や、より高い品質を実現するシステムに向けて進化するQ-upSystemやAOI/AXIを支えるデータ収集・分析基盤として、データや処理を追加し、システム進化を加速させる予定である。
最後に、今回の開発に多大なご協力をいただいた検査システム事業部の方々に深く感謝申し上げます。
参考文献
- 1)
- 森弘之,岸本真由子.AOIとマウンタの連携による故障予知システムQ-upAuto.OMRON TECHNICS 162.2019, Vol.51, No.1, p.105-111.
- 2)
- Inmon, W. H. Building the Data Warehouse. 1992, 272p.
Windowsは、米国Microsoft Corporationの米国およびその他の国における登録商標です。
Intel® Core、Intel® Xeon®は、Intel Corporationの米国およびその他の国における登録商標です。
本文に掲載の商品の名称は、各社が商標としている場合があります。