














生産条件の最適化における精度と効率を両立する転移学習技術
- 転移学習
- 実験計画法
- SVR
- 品質管理
- 最適生産条件
ものづくりにおいては、実験計画法に代表される統計的手法を用いて生産条件の最適化を行うことが重視されている。しかし、先見知識の活用などにより実験数を削減する場合が多いため、生産条件から製品品質を予測する応答曲面モデルに十分な精度が得られない場合がある。本稿では、他の領域で収集した情報を活用することで効率的な学習を実現する手法である転移学習に着目し、少数の実験しか実施しない場合にも、過去の実験データを学習に取込むことで、より精度の高い応答曲面モデルの構築手法を提案する。また、実験用包装機を対象に効果検証を実施した。その結果、十分な実験回数を実施し構築した応答曲面モデルの予測精度(RMSE=12.0)と比較して、提案手法を用いることで、実験回数を約1/3に制限した場合でも予測精度を約25%向上させることができた。
1.まえがき
ものづくりの現場において人手不足がますます深刻化している状況下でも、高いレベルでの品質保証と生産性の向上が求められている。この要求に対応するため、ものづくりプロセスの上流から下流にわたってデータを活用した品質管理が進められている。企画・設計段階では、様々な条件で実験が行われ、生産条件と品質の関係を把握し、設計・製造に反映することで安定して良品を生産する製造ラインを目指している。しかし、サプライヤーの変更や生産拠点の移転に伴う環境の変化、生産設備の置き換えなど、設計段階では想定が困難な事象が発生する場合があり、品質への影響が懸念される。また近年では、米中貿易摩擦や新型コロナウイルス感染症の拡大を背景に、設備投資先送りに伴う老朽化設備の継続使用も品質への影響が懸念される1)。このような事象などによって品質に影響がある場合にも、生産条件の見直しや設計変更を見据えた実験が行われる場合がある。
このとき、実験の目標の一つは、得られたデータから生産条件と品質の関係をモデル化することである。この目標に対して、効率的かつ精度よくモデル化するための実験方法および解析手法として実験計画法が知られている。しかし、実験計画法を用いたとしても推奨される実験回数が多いため、先見知識などによって実験回数を削減することが多い2)。そのため、考慮されなかった因子の影響や、実験範囲が適切でないなどの理由でモデルの精度が出ず、追加で実験が必要となる場合は少なくない3)。したがって、製造現場では、より少ない実験回数で精度の良いモデルを構築することが求められている。
実験回数を削減した場合でも、精度の良いモデルを構築する方法はいくつか提案されており、先見知識やシミュレーションを活用する方法4)と、対象の製造現場と類似するデータを活用する方法5)に分類できる。製造現場では先見知識が定式化されていない場合が多いため前者の方法は実施が困難である。一方、設備劣化や製造ラインの移転などの事象が発生しても製品が同じであれば、生産条件と品質の関係は類似した数式で表現されると考えられる。我々はこの考えのもと後者の方法において、品質に影響のある事象が発生した状態で取得したデータに、過去に同製品の製造ラインを立上げた時に取得したデータを反映させてモデル構築する手法を検討した。本稿では、特に製造現場で想定されるモデルの複雑さに対応しつつ、可能な限りシンプルな方法を提案する。
2.提案手法
2.1 提案手法の概要
新しい製品に対する設計からライン立上げ完了までを「立上げ時」、設備劣化や製造ラインの移転など品質に影響のある事象が発生し、品質の調整が必要になった場面を「品質調整時」とする。提案手法として、各場面におけるデータ取得とモデル構築の概要を図1に示す。
立上げ時:
- ①
- 実験計画法に基づいて、すべての調整項目を対象に十分なデータ取得を行う
- ②
- ①の取得データに対する回帰分析により応答曲面モデルを構築し、最適な生産条件を特定する
品質調整時:
- ③
- 先見知識を活用し実験計画法の考え方に基づいて、実験回数を制限したデータ取得を行う
- ④
- 転移学習により、③の取得データに対する回帰分析に①の取得データを活用して応答曲面モデルを構築し、最適な生産条件に修正する
ここで、応答曲面モデルとは生産条件と品質の関係をモデル化したものである。生産条件を決定する調整項目を説明変数 、品質を定量的に表す品質指標を応答変数
、品質を定量的に表す品質指標を応答変数 とすると、応答曲面モデルは関数
とすると、応答曲面モデルは関数 ()を使って式(1)で表される。
()を使って式(1)で表される。

ここで、 はノイズである。応答曲面モデルは品質調整時の生産条件の最適化の他、生産速度に応じた生産条件の変更によるタクトタイムの短縮や、製造メカニズムの追究など様々な用途に役立てられる。
はノイズである。応答曲面モデルは品質調整時の生産条件の最適化の他、生産速度に応じた生産条件の変更によるタクトタイムの短縮や、製造メカニズムの追究など様々な用途に役立てられる。
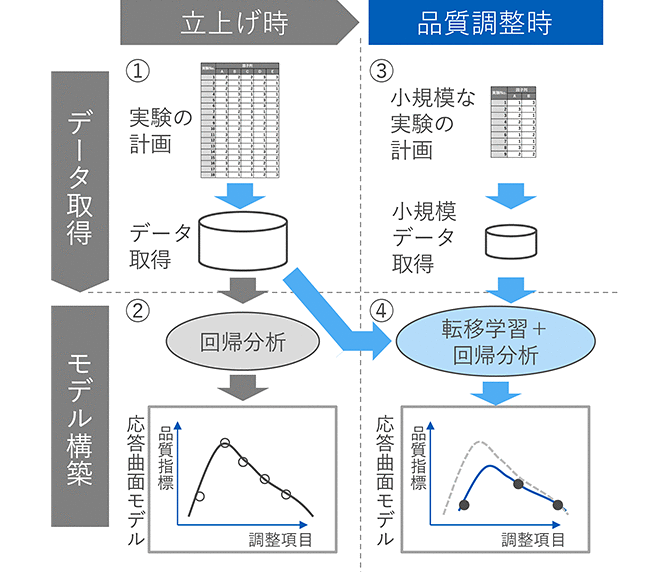
本提案手法の狙いは、実験計画法により取得データの質を担保した上で、転移学習と回帰分析を組み合わせることで、立上げ時のデータの特徴を考慮した応答曲面モデルを構築することである。これにより、小規模なデータしか取得しない場合でも、精度の良い応答曲面モデルの構築を図る。
次節以降では、提案手法における各要素技術(実験計画法、転移学習、回帰分析)について、技術概要と提案手法における適用方法について述べる。
2.2 実験計画法(Design of Experiments)
実験計画法とは因子(調整項目)が特性(品質指標)にどのような影響を与えるのかを精度よくかつ効率的に把握するための、実験方法および実験データの解析方法に関する統計手法の総称である。特に、すべての因子とすべての水準の組み合わせに対して実験を実施する計画を要因配置計画といい、因子が多数の場合に、要因配置計画の実験回数を直交性などの統計的観点から削減した計画を一部実施計画という。また、実験数を削減しつつ応答曲面モデル構築に必要なデータの質とのバランスを考慮した中心複合計画や、実験回数の制限のもとで最適な計画を提供する最適計画など、目的に応じて多種の手法が存在する。
いずれの手法においても、一般に実験回数と実験データから得られる応答曲面モデルの予測精度にはトレードオフの関係がある。実験回数が少ない場合には、高次の効果や因子間の交互作用などが考慮されず、予測精度低下のリスクは大きくなる。
2.3 転移学習(Transfer Learning)
目的とする領域(目標ドメイン、Target Domain)で得られたデータから学習する際に、別の領域(元ドメイン、Source Domain)で得られたデータや特徴を取り込むことで、目標ドメインでの学習の効率化や、より予測精度の高いモデルの構築を実現する手法である。
転移学習では元ドメインと目標ドメインがどのような観点で類似しているのかを仮定する。類似性がほとんどない場合や、類似性の観点に対して転移学習手法が適切でない場合は、元ドメインの情報がうまく転移されず効果が期待できない。このような場合、転移の効果が得られないばかりか、性能が悪化する場合もあり、負の転移と呼ばれる6)。
本稿では、立上げ時と品質調整時における製造ラインの状態を、それぞれ元ドメイン、目標ドメインとして扱う。品質調整時の応答曲面モデルは立上げ時から変化していると考えられるため、単純に立上げ時と品質調整時の取得データを結合するだけでは精度のよい応答曲面モデルを構築できない場合が多い。一方、製造する製品や製造方法に違いはないため、立上げ時と品質調整時の応答曲面モデルは似た数式で表現でき、転移学習における類似性として仮定することで、転移の効果が期待できる。
このような類似性の仮説と、2.1節で述べた状況設定より、転移学習手法の要件として以下を設定した。
- 回帰分析手法に適用可能であること
- 学習データ数は数10~数100程度(学習データ数=実験条件数×サンプル数であり、実験計画法における実験条件数は30程度までが多いため)
転移学習の研究事例の多くは分類問題(画像識別など)であり、回帰分析への適用事例においても、ビッグデータを前提とした深層学習を対象とした事例がほとんどである。
上記の要件を満たす手法としてはCORAL(Correlation Alignment)7)、FEDA(Frustratingly Easy Domain Adaptation)8)がある。CORALは元ドメインの分散共分散行列が目標ドメインに適合するように変換する手法のため、学習データの非線形性には対応ができない。従って本稿では、FEDAを採用した。FEDAは図2に示すように、元ドメインのデータと目標ドメインのデータに対して0ベクトルを連結し列方向に3倍のデータ拡張を行ったうえで、任意の学習アルゴリズムの学習データとして扱う手法である。
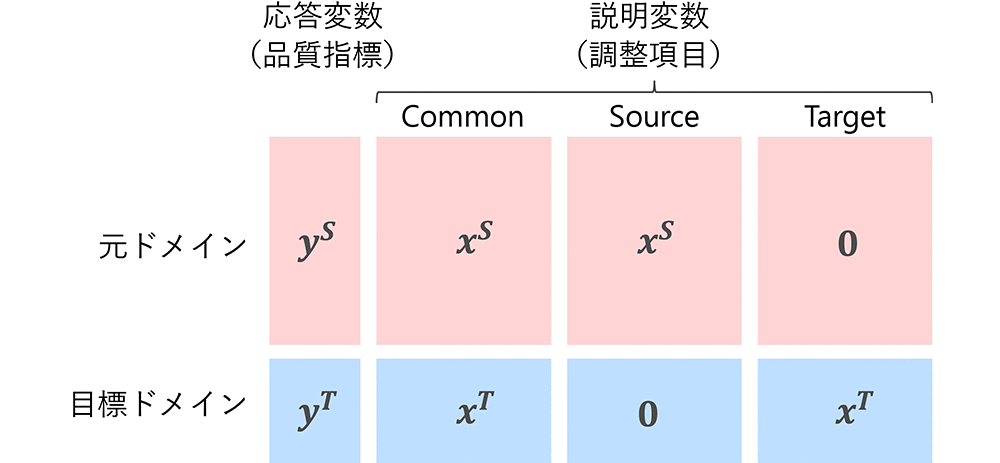
そのため、モデリング手法に制限がない。データ拡張により、学習時に目標ドメインと元ドメインで共通する特徴、目標ドメインまたは元ドメインのみの特徴を自然に使い分けて学習することができる。これにより、元ドメインから取り込む特徴をコントロールできるため、負の転移が起きにくいことが期待される。
具体的な処理内容について述べる。元ドメインおよび目標ドメインの学習データをそれぞれ式(2)で表す。

ここで、 ,
, と
と ,
, は各ドメインの応答変数および説明変数であり、
は各ドメインの応答変数および説明変数であり、 ,
, は各ドメインの学習データ数である(+=
は各ドメインの学習データ数である(+= )。元ドメインの学習データ(,)を(,〈,,0〉)に、目標ドメインの学習データ(,)を(,〈,0,〉)にそれぞれ拡張する。それぞれ拡張したデータを行方向に結合したうえで、通常の方法で学習する。
)。元ドメインの学習データ(,)を(,〈,,0〉)に、目標ドメインの学習データ(,)を(,〈,0,〉)にそれぞれ拡張する。それぞれ拡張したデータを行方向に結合したうえで、通常の方法で学習する。
さらに、2.4節に述べるカーネル法を用いたモデリング手法に適応する場合、高次元空間への写像による特徴量 (
( )に対してデータ拡張を行うことが可能である。元ドメインと目標ドメインの説明変数,の特徴量(),()は、それぞれ〈(),(),0〉,〈(),0,()〉に拡張される。,
)に対してデータ拡張を行うことが可能である。元ドメインと目標ドメインの説明変数,の特徴量(),()は、それぞれ〈(),(),0〉,〈(),0,()〉に拡張される。, を元ドメインまたは目標ドメインのデータとする。拡張された特徴量に対するカーネル関数
を元ドメインまたは目標ドメインのデータとする。拡張された特徴量に対するカーネル関数 (,)は、とのドメインが同じ場合と異なる場合で分けて計算すると、元のカーネル関数
(,)は、とのドメインが同じ場合と異なる場合で分けて計算すると、元のカーネル関数 (,)=((),())を使って、式(3)で表すことができる。
(,)=((),())を使って、式(3)で表すことができる。

式(3)は構築した応答曲面モデルを用いて目標ドメインの未知のデータに対して予測を行う場合には、目標ドメインから学習した重みが元ドメインの2倍で計算されることを意味する。したがって、元ドメインからの情報を取り込みつつ目標ドメインの予測を行うことが可能になる8)。
本稿では、前者のデータ拡張後に通常の方法で学習する方式をSimple-FEDA(s-FEDA)、後者のカーネル法に対応した手法をKernelized-FEDA(k-FEDA)と呼ぶこととする。
2.4 回帰分析(Regression Analysis)
応答曲面モデルを構築するための回帰分析手法に制限はないが、実験計画法においては2次多項式回帰がよく用いられる。しかし、2次多項式回帰の場合、モデルの構造が単純で解釈がしやすい一方、因子と応答の関係が複雑な場合には精度が期待できない。そのため、因子と応答に多項式では表現できない複雑な関係が想定される場合には、非線形回帰が有効である。
主な非線形回帰手法としてニューラルネットワーク回帰(Neural Network,NN)9)、ガウス過程回帰(Gaussian Process Regression,GPR)10)サポートベクトル回帰(Support Vector Regression,SVR)11)が挙げられる。NNは調整すべきハイパーパラメータが多いため学習が難しく、学習にかかる時間も長い。また、GPRはパラメータ調整が容易であるものの、全てのデータを使ってモデル構築するため計算量が多く複雑なモデルになりやすい。一方、SVRはパラメータ調整が容易であり、一部の重要なデータのみを使ってモデル構築するためシンプルなモデルが得やすい。以上より本稿では回帰分析手法としてSVRを採用した。
SVRはカーネル法を用いた非線形回帰手法である。カーネル法はデータをそのまま学習するのではなく、高次元空間に写像してから学習することで、非線形性の学習を可能にする方法である。さらに、前述のFEDAとの組合せる意義として、
- カーネル法を用いているため、k-FEDAによるモデル構築ができる(式(3))
- FEDAと2次多項式回帰を組合せた場合、元ドメインと目標ドメインを個別にモデルリングすることと同義になり、転移の効果が得られない
という点が挙げられる。
SVRにおけるモデル式は高次空間への写像を使って、

と表される。許容誤差(-insensitive error)を導入し、最適化問題(式(5)(6))


をLagrangeの未定乗数法で解くことによってモデル式(7)が得られる。

ここで、 ,
, はLagrange定数、
はLagrange定数、 とはハイパーパラメータである。は予測誤差と正則化のバランスを調整し、は許容誤差の幅を制御する。正則化と許容誤差の効果により、モデルの表現に有効な学習データのみ抽出される。これより、データに対する予測は、一部の学習データ
とはハイパーパラメータである。は予測誤差と正則化のバランスを調整し、は許容誤差の幅を制御する。正則化と許容誤差の効果により、モデルの表現に有効な学習データのみ抽出される。これより、データに対する予測は、一部の学習データ に対応するカーネル関数の値の線形結合によって行われる。
に対応するカーネル関数の値の線形結合によって行われる。
また、カーネル関数(,)はガウシアンカーネル(radial basis function,RBF)、多項式カーネル、シグモイドカーネルなどが使用される。カーネル関数の形状を規定するハイパーパラメータも存在し、一般的にはグリッドサーチによってクロスバリデーション後の予測精度が最も良くなるハイパーパラメータを採用する。
3.机上実験
提案手法の原理検証のため人工の学習データを対象とした机上実験を実施した。
3.1 実験概要
人工的に生成した学習データの内訳を表1に示す。実際のユースケースを想定し、元ドメインと目標ドメインに対応する2つの真のモデル ()を設定する。入力(
()を設定する。入力( =1,2,...
=1,2,... )に対する出力
)に対する出力 を
を

によって、元ドメインと目標ドメインをそれぞれ生成した。ここで、 〜(0,1)はノイズである。また、学習データ数は、目標ドメインでは少数であることを想定し、元ドメインと目標ドメインで10:1となるようにした。
〜(0,1)はノイズである。また、学習データ数は、目標ドメインでは少数であることを想定し、元ドメインと目標ドメインで10:1となるようにした。
| Domain | F(x) | Ntrain −5 ≤ x ≤ 5 |
Ntest −10 ≤ x ≤ 10 |
|---|---|---|---|
| Source | 0.2x2−0.2x+3 | 100 | |
| Target | 0.2x2−0.3x+0.5 | 10 | 100 |
適用する提案手法の構成として、転移学習手法にはFEDA(s-FEDA,k-FEDA)、回帰分析手法はSVRを対象とする。SVRのカーネル関数は後述の高速化手法が利用可能なRBFを採用した。RBFは式(9)で表される。

 は関数の形状を規定するハイパーパラメータである。SVRのハイパーパラメータ,,調整には先行研究で提案されている高速化手法を用いた12)。
は関数の形状を規定するハイパーパラメータである。SVRのハイパーパラメータ,,調整には先行研究で提案されている高速化手法を用いた12)。
生成した学習データに対して転移学習の有無を含む各手法(SVR,SVR+s-FEDA,SVR+k-FEDA)を適用し、応答曲面モデルを構築した。
3.2 実験結果
各手法で構築した応答曲面モデルを用いて目標ドメインの真値を予測し、各手法の性能を比較する。外挿に対する汎化性能を確認するため、学習データよりも広いの範囲に対する真値()(=1..., )を予測し誤差を評価した。予測誤差はRMSE(Root Mean Square Error)(式(10))で評価した。ここで、
)を予測し誤差を評価した。予測誤差はRMSE(Root Mean Square Error)(式(10))で評価した。ここで、 (=1,...,)は予測値である。
(=1,...,)は予測値である。

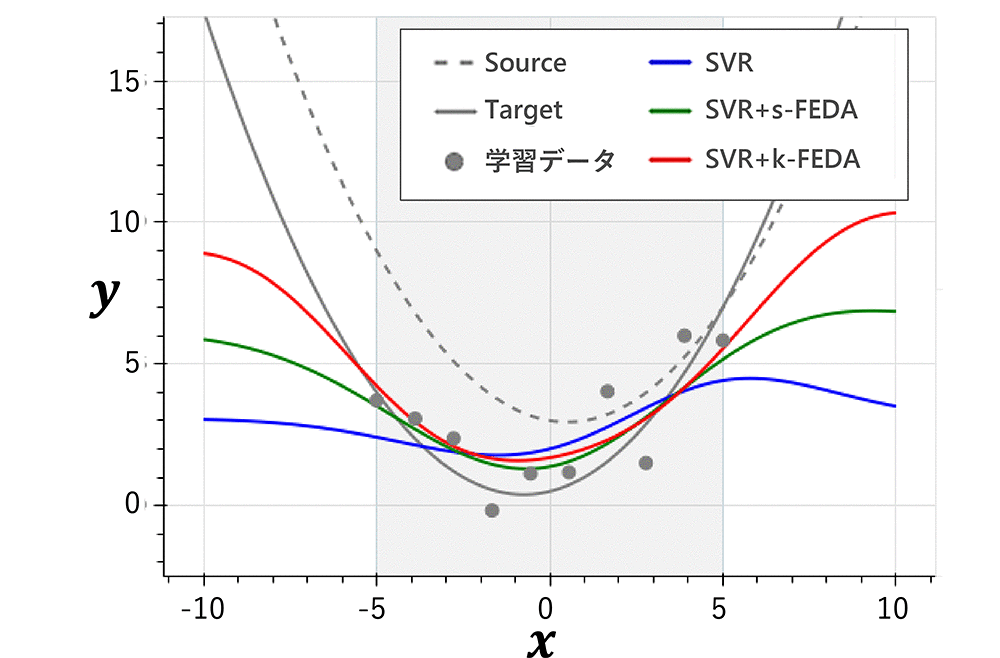
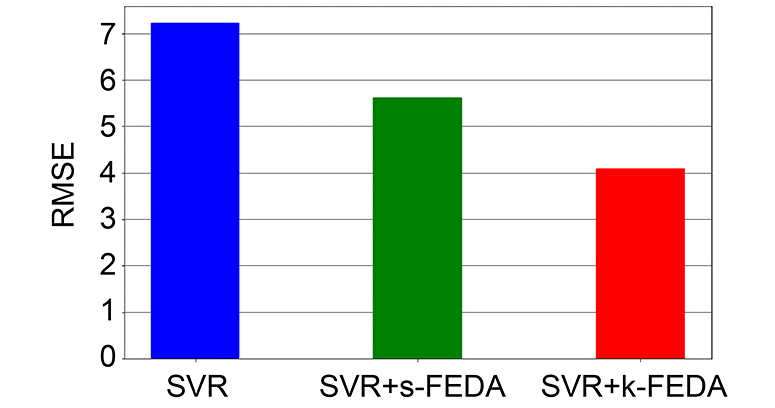
評価結果として各手法で構築した応答曲面を図3、RMSEを図4に示す。図3においてグレーの領域は学習データの範囲、データ点は目標ドメインの学習データを示す。
提案手法を用いない場合(SVR)は学習データが少ないため予測誤差が大きいが、提案手法を用いた場合(SVR+s-FEDA,SVR+-k-FEDA)は、学習データが豊富な元ドメインのモデル形状に近づき、結果として予測精度が向上している。特にSVR+k-FEDAの方が元ドメインのモデル形状からの乖離が小さく、汎化性能が良いことが確認できた。これは、SVR+k-FEDAでは式(3)に示した通りドメインの違いは単純な係数で表現されるが、SVR+s-FEDAではデータ拡張後に高次元空間への写像を適用するため、ドメインの違いが複雑な表現になることが理由として考えられる。
以上より、SVR+k-FEDAを適用することで元ドメインの応答曲面モデルの形状を考慮した目標ドメインの応答曲面モデルが得られることが期待できる。よって、次章の実機での効果検証では、SVR+k-FEDAを採用した。
4.実機での効果検証
本章では、3章で検証した提案手法を実験用の横型ピロー包装機に適用し、有効性を検証した結果を述べる。
4.1 検証概要
効果検証の対象となる横型ピロー包装機の構成を図5に示す。
包装機に搬入されたワークは、センターシールヒータにより筒状に成形されたフィルムに包まれつつプレスローラにより搬送される。そして、トップシール工程でワーク前後のフィルムを溶着しつつロータリカッターで切り離されることで枕状に包装され、製品となる。プログラマブル・ロジック・コントローラ(PLC)による温度や速度などの厳密な制御の他、設備状態や製品仕様に応じた機械的な調整によって、目的の製品の製造を実現してい13)。
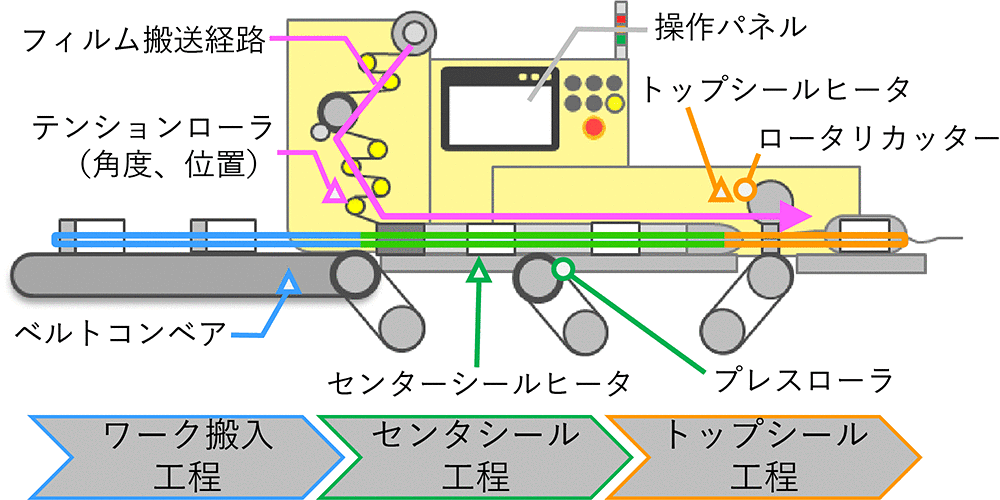
本稿では、包装機において設備劣化により品質異常が発生した場合に、実験計画法に基づいて応答曲面モデルを構築し、最適な生産条件を特定して生産を再開するというユースケースを想定し、有効性を検証する。
具体的な設備劣化としては、センターシール工程でフィルムを挟み込んで送り出すための部品であるプレスローラが磨耗することでセンターシールが溶着不良となる「プレスローラ磨耗」を対象とした。実際の検証では磨耗した部品を用意することが困難なため、プレスローラの調整ネジを緩めて、フィルムの挟み込みのギャップ幅を広げることで設備劣化を再現した。
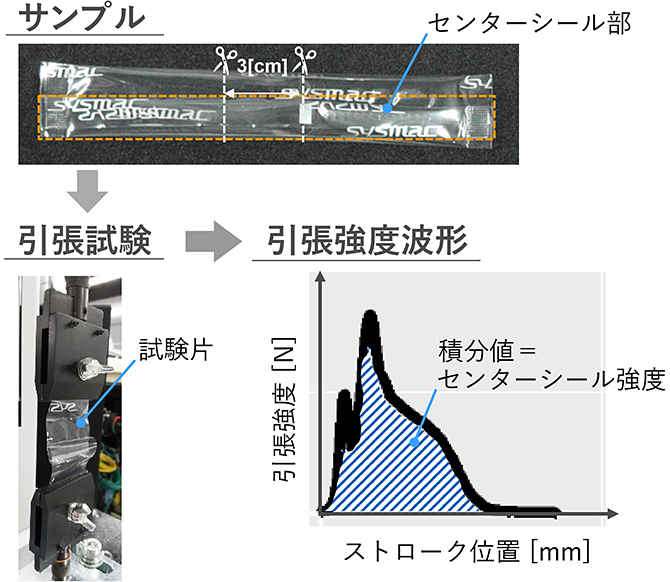
プレスローラ磨耗により発生する品質異常に紐づく品質指標は「センターシール強度」とした。図6にセンターシール強度の計測方法を示す。JIS Z0238に準拠した機材および測定方法でセンターシール部の引張強度を計測し、溶着面の強さ(引張エネルギー)として算出した指標である14)。具体的にはサンプルから切り取った試験片を引張試験にかけ、負荷のかかり始めから溶着面が完全に離れるまで(1ストローク分)の強度[N]の波形を取得しPCに時系列波形として取り込む。そして、1ストローク分の時系列波形の積分値を品質指標であるセンターシール強度として算出した。
そして、品質指標に影響を与える可能性があり、調整可能な調整項目として包装速度[CPM]、センターシール温度[℃]、トップシール温度[℃]、ローラ角度[°]、ローラ位置[cm]の5つを選定した。包装速度、センターシール温度、トップシール温度は操作パネルを用いて調整した。ローラ角度、ローラ位置はフィルムがセンターシール工程と合流する際の侵入角度と位置を決める機械的な調整項目である。
4.2 検証用データの取得
転移学習における元ドメインと目標ドメインとなる「立上げ時」「劣化(小規模)」、効果検証のリファレンスとなる「劣化時(大規模)」の3つのドメイン(状態)でデータ取得を行った。
「立上げ時」は包装機の新規立上げ時の設備劣化が起こる前の状態であり、前述の5つの調整項目すべてについて実験を行った場合である。「劣化時(大規模)」は設備劣化が発生した状態で、実験回数を制限せず5つの調整項目について実験を行った場合である。「劣化時(小規模)」も設備劣化の状態であるが、先見知識よりセンターシール強度への影響が大きい2つの調整項目(包装速度、センターシール温度)に限定して実験を行った場合である。各ドメインの学習データの内訳を表2に、実験計画の概要を表3に示す。実験計画手法には、少ない実験数で比較的高いモデリング精度が確保できる中心複合計画を採用した。
| 項目 | ドメイン | |||
|---|---|---|---|---|
| 立上時 | 劣化時 (大規模) |
劣化時 (小規模) |
||
| 学習データ | 調整項目数 | 5 | 5 | 2 |
| 実験条件数 | 31 | 28 | 10 | |
| データ数 | 358 | 273 | 112 | |
| テストデータ | 調整項目数 | 2 | ||
| 実験条件数 | 5 | |||
| データ数 | 60 | |||
| 調整項目 | ドメイン | ||
|---|---|---|---|
| 立上時 | 劣化時 (大規模) |
劣化時 (小規模) |
|
| 包装速度[CPM] | 12〜108 | 5〜80 | 12〜68 |
| センターシール 温度[℃] |
135〜200 | 140〜200 | 152〜200 |
| トップシール温度 [℃] |
130〜200 | 130〜200 | 130 |
| ローラ角度[°] | 150〜158 | 150〜158 | 154 |
| ローラ位置[cm] | 9.8〜14.6 | 9.8〜14.6 | 12.2 |
各調整項目の水準は、包装機固有の先見知識や事前の試行結果、構造上・仕様上設定可能な範囲に基づいて、調整範囲内に多くの良品が含まれるよう設定した。実際には、各調整項目の水準は3水準から5水準とした。なお、劣化時(小規模)では、実験対象外の3つの調整項目(トップシール温度、ローラ角度、ローラ位置)は、過去に良品生産の実績がある標準条件(トップシール温度=130[℃]、ローラ角度=154[°]、ローラ位置=12.2[cm])で一定値とした。このとき、立上げ時と劣化時(大規模)のトップシール温度の水準は、標準条件(130[℃])を下限値とする調整範囲で設定している。これはトップシール温度が130[℃]を下回ると溶着されず未包装のサンプルが頻発するためである。
各実験条件において、ワークを投入せずに包装機を稼働させて100個以上のサンプルを製造し、製造したサンプルから12個無作為抽出し、センターシール強度を計測した。なお、実験条件によってはセンターシール部が溶着されず、品質指標が欠損するため、学習データ数が少なく12の倍数にはならない。
4.3 検証結果
製造方法および原理に変更はないため立上げ時と劣化時で真のモデルは類似していると想定する。この想定のもと、前節で述べた学習データに各手法を適用することで応答曲面モデルを構築し、テストデータに対する予測誤差としてRMSEを算出し、各モデルの性能を比較した。
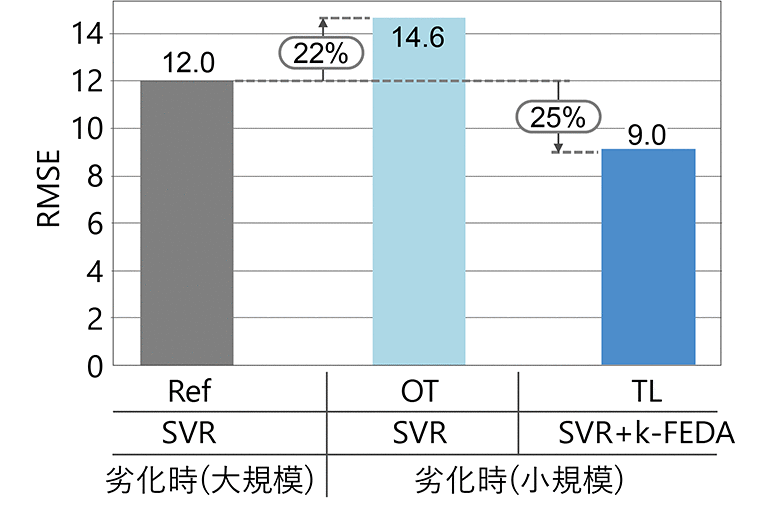
構築した応答曲面モデルは、リファレンスとなる劣化時(大規模)にSVRを適用したモデル(Ref,reference)、劣化時(小規模)のみにSVRを適用したモデル(OT,only target)、立上げ時と劣化時(小規模)に提案手法を用いて構築したモデル(TL,transfer learning)の3つである。性能評価に使用したテストデータを表2に示す。各モデルのテストデータは共通している。テストデータの実験条件は学習データとは異なる実験条件とし、学習データ取得時と同様の方法でデータを取得した。なお、包装速度とセンターシール温度以外の調整項目は品質指標への影響が小さいことから、標準条件で一定値とした。
各モデルのテストデータに対するRMSEを図7に示す。Refと比べて、実験数を制限したOTの精度が22%低下している。しかし、劣化時(小規模)に対して提案手法を用いたTLでは、Refを25%上回る精度に向上している。
なお、各モデルの構築に要した時間はRef,OTが約1.5秒、TLが約20秒であった。TLは他のモデルと比較して学習データ数が多く、式(3)に基づくカーネル関数の再計算を行っていることが影響していると考えられる。
4.4 考察
学習データにおいては、立上げ時が他のドメインと比べて実験条件数が多く、最も密に水準が設定されている。また、劣化時と立上げ時の真のモデルの類似性を想定していた。転移学習により、劣化時(小規模)または劣化時(大規模)の実験データでは表現できない水準間の中間の状態が表現できるようになった結果、精度が向上したと考えられる。したがって、提案手法による効果を得るには、元ドメインの学習データが網羅的に取得されており、元ドメインと目標ドメインの真のモデルが類似することが重要であると考えられる。
表2に示した通り、劣化時(小規模)の実験条件数は劣化時(大規模)の約1/3(=10/28)である。すなわち、製造現場において実験数を1/3に削減したとしても、精度よく品質予測が行えることを意味している。これは、今回の検証環境と同様の製造現場において、品質調整にかかる工数を2日間短縮可能であると言える。
また、TLに基づいて推定した最適な生産条件に設定し、製造したサンプルの品質指標を確認した。推定した生産条件における品質指標の平均値(44.4[N*mm])は、学習時に安定して良品生産できた実験条件での品質指標の平均値(31.5~50.6[N*mm])と同程度であることが確認できた。センターシール強度はある程度の温度以上ではほとんど変化しない15)。したがって、本検証におけるセンターシール強度の最適な生産条件も広い領域に存在すると考えられ、推定した生産条件は最適な生産条件の一つであると考えられる。
以上より、提案手法により、品質調整時に大規模な実験を行わず主要な調整項目に絞った実験を行うだけで、高精度に最適な生産条件を特定できることが期待できる。
4.5 今後の課題
本提案手法では、2.4節で述べた負の転移が起こりにくい手法を選定しているものの、可能性をゼロにすることは不可能である。実際には、応答曲面モデルを構築し、推定した生産条件で試行することでしか、負の転移の発生を確認することができない。
しかし、実際の製造現場での使用性を考えると、推定した生産条件での試行以前に負の転移の有無をユーザが判断できることが望ましい。使用性の向上には、元ドメインと目標ドメインの学習データの統計的な類似性を事前に判断し、その判断結果に応じて学習手法を使い分けることが有効と考えられる16)。
5. むすび
本稿では、自動化された製造ラインにおいて様々な変動要因によって品質異常が発生した場面を対象に、少ない実験回数でも精度の良い応答曲面モデルを構築することを目的として、SVRとFEDAを組み合わせた解析手法を提案した。さらに、実験用包装機を対象とした効果検証を実施し、様々な生産条件が試行される立上げ時のデータを活用することで、品質調整時の応答曲面モデルの精度向上が期待できることを示した。
今後の展望としては、能動学習(Active Learning)との組み合わせにより効率的な手法の開発や、品質指標のばらつきまで考慮した多応答の最適化への展開など、多種多様な製造現場のニーズに対応できる技術に進化させていきたい。
参考文献
- 1)
- 経済産業省.“2020年度版ものづくり白書”.https://www.meti.go.jp/report/whitepaper/mono/2020/index.html,(参照 2020-10-30).
- 2)
- 一般社団法人 日本品質管理学会中部支部 産学連携研究会.開発・設計に必要な統計的品質管理 トヨタグループの実践事例を中心に.平文社,2015,305p.
- 3)
- 森田 浩.実験計画法の基本と仕組み.秀和システム,2010,278p.
- 4)
- 武藤 和夫,小野寺 誠.事前知識を利用した応答曲面作成方法に関する検討とピンフィンヒートシンクへの適用.日本機会学会論文集.2019, Vol.85, No.880, p.19-00194.
- 5)
- Min, A. T. W. et al. Knowledge Transfer Through Machine Learning in Aircraft Design. IEEE Computational Intelligence Magazine. 2017, Vol.12, Issue 4, p.48-60.
- 6)
- 神嶌 敏弘.転移学習.人工知能学会誌.2010, Vol.25, No.4, p.1-9.
- 7)
- Sun, B.; Feng, J.; Saenko, K. Return of Frustratingly Easy Domain Adaptation. Proceedings of 30th AAAI Conference on Artificial Intelligence, 2016, p.2058-2065.
- 8)
- Daume, H. III. Frustratingly Easy Domain Adaptation. 45th Annual Meeting of the Association of Computational Linguistics. 2007, p.256-263.
- 9)
- ビショップ,C.M. パターン認識と機械学習 上.シュプリンガー・ジャパン,2012,349p.
- 10)
- 持橋 大地,大羽 成征,杉山 将.ガウス過程と機械学習.講談社.2019.
- 11)
- ビショップ,C.M. パターン認識と機械学習 下.シュプリンガー・ジャパン,2012,433p.
- 12)
- Kaneko, H.; Funatsu, K. Fast Optimization of Hyperparameters for Support Vector Regression Models with Highly Predictive Ability. Chemometrics and Intelligent Laboratory Systems. 2015, Vol.142, p.64-69.
- 13)
- 鶴田浩輔,峯本俊文,広橋佑紀.マシンコントローラに搭載可能なAI 技術の開発(1).OMRON TECHNICS. 2018, Vol.50, No.1, p. 6-11.
- 14)
- 菱沼 一夫.ヒートシールの基礎と実際―溶着面温度測定法:MTMS の活用―.幸書房,2007,197p.
- 15)
- 公益社団法人日本包装技術協会.包装技術便覧.2019.
- 16)
- メガチップス.西行 健太、藤吉 弘亘.クラスタリング装置及び機械学習装置,6516531 号.2016-11-10.
本文に掲載の商品の名称は、各社が商標としている場合があります。