専門知識なしで直感的に、ロボット動作の生成が可能
『きゅうりを切ってお皿に盛り付けて』等の日常会話で、映像と言葉から意図したロボット動作の手順を生成できるAI技術です。
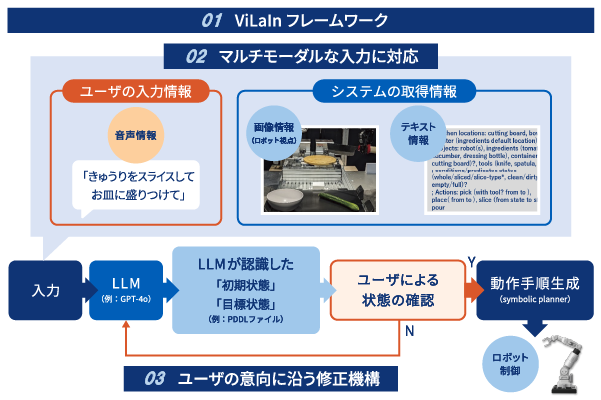
01 VilaIn フレームワーク
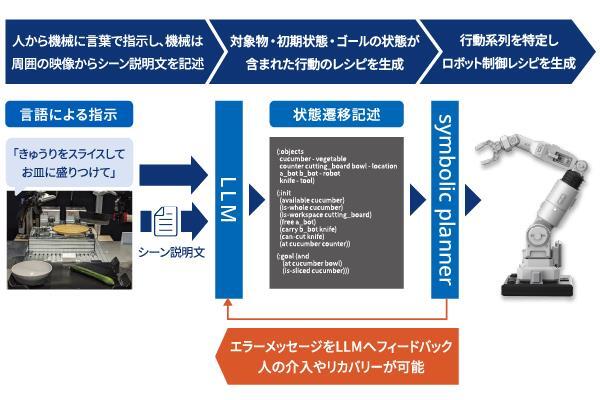
ユーザーの指示に基づき、LLMが「初期状態」から「目標状態」への動作手順を生成することで、専門知識無しでロボット制御を実現可能
- 解決可能な課題
- ・ロボット制御に高度な専門知識とプログラミングスキルが必要
・複雑な作業になればなるほど、動作手順の設計難易度が高くなる
02マルチモーダルな入力に対応
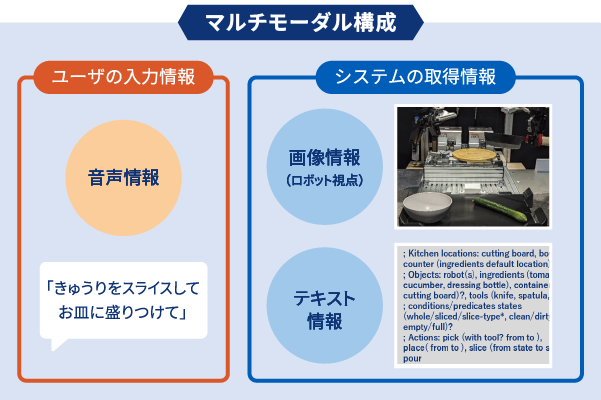
ユーザーは専門知識がなくても直感的にロボットへ指示が可能
- 解決可能な課題
- ・ロボットの指示には高度なプログラミングが必要
・音声や画像など複数の入力方法に対応していない
03ユーザーの意向に沿う修正機構
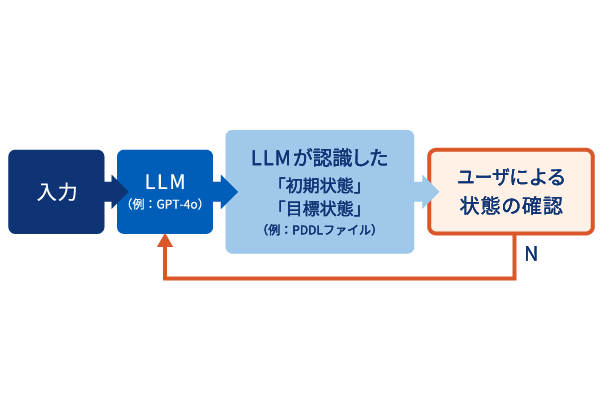
LLMからの生成に誤りがあった場合、ユーザーが修正できるフィードバックループにより指示通りの動作が実現可能
- 解決可能な課題
- ・LLMの誤出力によりロボットの意図しない動作による破損
・LLMの出力に対する信頼性が低下している
 カタログをダウンロード
カタログをダウンロード